资源
Transformer来自论文: All Attention Is You Need
别人的总结资源:
- 谷歌官方AI博客: Transformer: A Novel Neural Network Architecture for Language Understanding
- Attention机制详解(二)——Self-Attention与Transformer 谷歌软件工程师
- 一个是Jay Alammar可视化地介绍Transformer的博客文章 The Illustrated Transformer,非常容易理解整个机制,建议先从这篇看起,这是中文翻译版本;
- 放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较 中科院软件所 · 自然语言处理 /搜索 10年工作经验的博士(阿里,微博);
- Calvo的博客:Dissecting BERT Part 1: The Encoder,尽管说是解析Bert,但是因为Bert的Encoder就是Transformer,所以其实它是在解析Transformer,里面举的例子很好;
- 再然后可以进阶一下,参考哈佛大学NLP研究组写的“The Annotated Transformer. ”,代码原理双管齐下,讲得也很清楚。
- 《Attention is All You Need》浅读(简介+代码) 这个总结的角度也很棒。
总结
这里总结的思路:自顶向下方法
model architecture
一图胜千言,6层编码器和解码器,论文中没有说为什么是6这个特定的数字
Encoder
Decoder
如果我们想做堆叠了2个Encoder和2个Decoder的Transformer,那么它可视化就会如下图所示:
![]()
翻译输出的时候,前一个时间步的输出,要作为下一个时间步的解码器端的输入,下图展示第2~6步:
![]()
下面是一个单层:Nx 表示 N1, … , N6 层

parts
Multi-head Attention
其实就是多个Self-Attention结构的结合,每个head学习到在不同表示空间中的特征,所谓“多头”(Multi-Head),就是做h次同样的事情(参数不共享),然后把结果拼接。
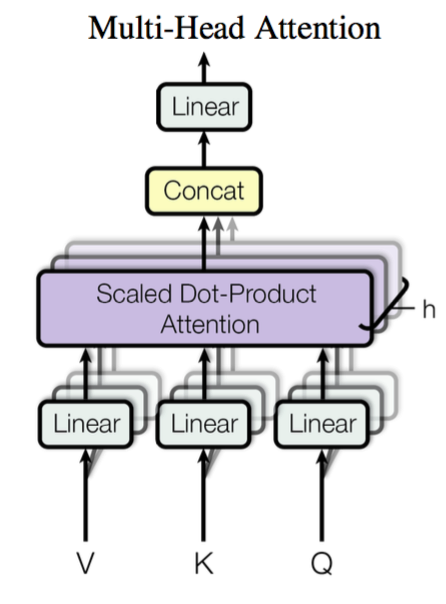
Self-Attention
实际上是scaled dot-product attention 缩放的点积注意力:

Add
residual connection: skip connection 跳跃了解
Norm
layer norm 归一化层
Positional encoding
google的这个位置编码很魔幻,是两个周期函数:sine cosine
数学系出生的博主的解释:《Attention is All You Need》浅读(简介+代码),相比之下Bert的位置编码直观的多。
