Preface
写这个阅读笔记之前,Hadoop YARN 的稳定发行版是:2.9.2 。
YARN Federation 思想源自:HDFS Federation,官方文档介绍,HDFS Federation 解决的是 NameNode 的横向扩展,HDFS HA 解决的是 NameNode 的单点问题。
Purpose
YARN is known to scale to thousands of nodes. The scalability of YARN is determined by the Resource Manager, and is proportional to number of nodes, active applications, active containers, and frequency of heartbeat (of both nodes and applications). Lowering heartbeat can provide scalability increase, but is detrimental to utilization (see old Hadoop 1.x experience). This document described a federation-based approach to scale a single YARN cluster to tens of thousands of nodes, by federating multiple YARN sub-clusters. The proposed approach is to divide a large (10-100k nodes) cluster into smaller units called sub-clusters, each with its own YARN RM and compute nodes. The federation system will stitch these sub-clusters together and make them appear as one large YARN cluster to the applications. The applications running in this federated environment will see a single massive YARN cluster and will be able to schedule tasks on any node of the federated cluster. Under the hood, the federation system will negotiate with sub-clusters resource managers and provide resources to the application. The goal is to allow an individual job to “span” sub-clusters seamlessly.
YARN 可以伸缩到数千个节点。 YARN 的可伸缩性由资源管理器决定,与节点数量、活动的应用程序、活动的容器和心跳频率(节点和应用程序)成正比。降低心跳可以提高可伸缩性,但不利于利用率(请参阅旧的Hadoop1.x体验)。本文描述了一种基于联邦(federation)的方法,通过将多个 YARN 子集群结成(federate)联邦,将单个 YARN 集群扩展到数万个节点。该方法将一个大的(10-100K节点)集群划分为更小的子集群单元,每个子集群都有自己的 YARN RM 和计算节点。联邦系统(federation system)将这些子集群结合(stitch)在一起,使它们成为应用程序中的一个大型 YARN 集群。在这个联合环境中运行的应用程序将看到一个单个巨大的 YARN 集群,并且能够在联邦集群的任何节点上调度任务。在幕后,联邦系统将与子集群资源管理器协商,并向应用程序提供资源。目标是允许单个作业无缝地“跨越”子集群。
This design is structurally scalable, as we bound the number of nodes each RM is responsible for, and appropriate policies, will try to ensure that the majority of applications will reside within a single sub-cluster, thus the number of applications each RM will see is also bounded. This means we could almost linearly scale, by simply adding sub-clusters (as very little coordination is needed across them). This architecture can provide very tight enforcement of scheduling invariants within each sub-cluster (simply inherits from YARN), while continuous rebalancing across subcluster will enforce (less strictly) that these properties are also respected at a global level (e.g., if a sub-cluster loses a large number of nodes, we could re-map queues to other sub-clusters to ensure users running on the impaired sub-cluster are not unfairly affected).
这种设计在结构上是可伸缩的,因为我们限制了了每个 RM 负责的节点的数量,并且适当的策略将尝试确保大多数应用程序将驻留在单个子集群中,因此每个 RM 将看到的应用程序的数量也是有界的。这意味着我们可以通过简单地添加子集群(因为在它们之间几乎不需要协调)来线性扩展。这种体系结构可以在每个子集群中提供对调度不变量进行非常严格执行(简单地继承自 YARN),而跨子集群的连续重新平衡将强制(不太严格)在全局级别上也遵守这些属性(例如,如果子集群丢失了大量的节点,我们可以将队列重新映射到其他子集群,以确保在受损子集群上运行的用户不会受到不公平的影响)。
Federation is designed as a “layer” atop of existing YARN codebase, with limited changes in the core YARN mechanisms.
联邦被设计为现有 YARN 代码库的顶“层”,核心 YARN 机制的变化有限。
Assumptions:
We assume reasonably good connectivity across sub-clusters (e.g., we are not looking to federate across DC yet, though future investigations of this are not excluded).
我们假设子集群之间具有相当好的连通性(例如,我们还不希望在整个DC之间建立联邦,尽管未来对此的调查并未排除在外)。
We rely on HDFS federation (or equivalently scalable DFS solutions) to take care of scalability of the store side.
我们依赖 HDFS 联邦(或同等可扩展的 HDFS 解决方案)来处理存储端的可扩展性。
Architecture
OSS YARN has been known to scale up to about few thousand nodes. The proposed architecture leverages the notion of federating a number of such smaller YARN clusters, referred to as sub-clusters, into a larger federated YARN cluster comprising of tens of thousands of nodes. The applications running in this federated environment see a unified large YARN cluster and will be able to schedule tasks on any nodes in the cluster. Under the hood, the federation system will negotiate with sub-clusters RMs and provide resources to the application. The logical architecture in Figure 1 shows the main components that comprise the federated cluster, which are described below.
据了解,OSS YARN 可以扩展到大约几千个节点。所提出的架构利用了一些较小的 YARN 集群(称为子集群)联合成由数万个节点组成的较大的联邦 YARN 集群的概念。在这个联邦环境中运行的应用程序可以看到一个统一的大型 YARN 集群,并且能够在集群中的任何节点上调度任务。在这种情况下,联邦系统将与子集群的 RMs 进行协商,并为应用程序提供资源。图1中的逻辑架构显示了组成联邦集群的主要组件,如下所述。
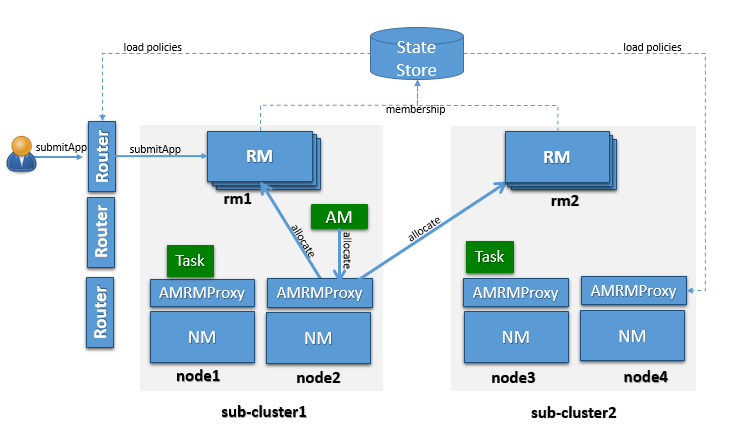
YARN Sub-cluster
A sub-cluster is a YARN cluster with up to few thousands nodes. The exact size of the sub-cluster will be determined considering ease of deployment/maintenance, alignment with network or availability zones and general best practices.
子集群是一个具有数千个节点的 YARN 集群。考虑到易于部署或维护、与网络或区域可用性以及通用最佳实践,将确定子集群的准确大小。
The sub-cluster YARN RM will run with work-preserving high-availability turned-on, i.e., we should be able to tolerate YARN RM, NM failures with minimal disruption. If the entire sub-cluster is compromised, external mechanisms will ensure that jobs are resubmitted in a separate sub-cluster (this could eventually be included in the federation design).
子集群 YARN RM 将在保持高可用性的情况下运行,即,我们应该能够承受 YARN RM、NM故障,且受损最小。如果整个子集群受到破坏,外部机制将确保在不同的子集群中重新提交作业(这可能最终包括在联邦集群设计中)。
Sub-cluster is also the scalability unit in a federated environment. We can scale out the federated environment by adding one or more sub-clusters.
子集群也是联邦环境中的可伸缩性单元。我们可以通过添加一个或多个子集群来扩展联邦环境。
Note: by design each sub-cluster is a fully functional YARN RM, and its contribution to the federation can be set to be only a fraction of its overall capacity, i.e. a sub-cluster can have a “partial” commitment to the federation, while retaining the ability to give out part of its capacity in a completely local way.
注:根据设计,每个子集群都是一个功能齐全的 YARN RM,其对联邦的贡献可以设置为其总容量的一小部分,即子集群可以对联邦“部分”承诺,同时保留了部分容量完全给本地运行的的能力。
Router
YARN applications are submitted to one of the Routers, which in turn applies a routing policy (obtained from the Policy Store), queries the State Store for the sub-cluster URL and redirects the application submission request to the appropriate sub-cluster RM. We call the sub-cluster where the job is started the “home sub-cluster”, and we call “secondary sub-clusters” all other sub-cluster a job is spanning on. The Router exposes the ApplicationClientProtocol to the outside world, transparently hiding the presence of multiple RMs. To achieve this the Router also persists the mapping between the application and its home sub-cluster into the State Store. This allows Routers to be soft-state while supporting user requests cheaply, as any Router can recover this application to home sub-cluster mapping and direct requests to the right RM without broadcasting them. For performance caching and session stickiness might be advisable. The state of the federation (including applications and nodes) is exposed through the Web UI.
YARN 应用程序被提交到其中一个路由器(Router),该路由器依次应用路由策略(从 Policy Store 中获得),查询 Policy Store 得到子集群 URL,并将应用程序提交的请求重定向到相应的子集群 RM。我们将启动作业的子集群称为“home sub-cluster”,并将作业所跨越的所有其他子集群称为“secondary sub-cluster”。路由器向外界公开ApplicationClientProtocol,透明(transparently )地隐藏多个 RMs 的存在。为了实现这一点,路由器(Router)还将应用程序与其 home sub-cluster 之间的映射一直保存到 State Store 中。这允许路由器处于软状态(soft-state),同时以较低的成本支持用户请求,因为任何路由器都可以将此应用程序恢复到 home sub-cluster 映射,并将请求直接发送到正确的 RM,而无需广播它们。对于性能缓存(performance caching)和会话粘性(session stickiness)可能是明智的。联邦状态(包括应用程序和节点)通过Web UI公开。
AMRMProxy
The AMRMProxy is a key component to allow the application to scale and run across sub-clusters. The AMRMProxy runs on all the NM machines and acts as a proxy to the YARN RM for the AMs by implementing the ApplicationMasterProtocol. Applications will not be allowed to communicate with the sub-cluster RMs directly. They are forced by the system to connect only to the AMRMProxy endpoint, which would provide transparent access to multiple YARN RMs ( by dynamically routing/splitting/merging the communications ). At any one time, a job can span across one home sub-cluster and multiple secondary sub-clusters, but the policies operating in the AMRMProxy try to limit the footprint of each job to minimize overhead on the scheduling infrastructure (more in section on scalability/load). The interceptor chain architecture of the ARMMProxy is showing in figure.
AMRMProxy 是允许应用程序在子集群之间扩展和运行的关键组件。AMRMProxy 运行在所有 NM 机器上,通过实现 ApplicationMasterProtocol 作为 AMs 的 YARN RM的代理。不允许应用程序直接与子集群 RMs 通信。它们被系统强制只连接到 AMRMProxy 端点,这将提供对多个 YARN RMs 的透明(transparently)访问(通过动态路由/拆分/合并通信)。在任何时候,一个作业都可以跨越一个 home sub-cluster 和多个 secondary sub-clusters,但是 AMRMProxy 中运行的策略试图限制每个作业的占用空间,以最小化在负责调度的基础结构(scheduling infrastructure)上的开销(更多内容请参见可伸缩性/负载部分)。AMRMProxy 的拦截器链结构如图所示。
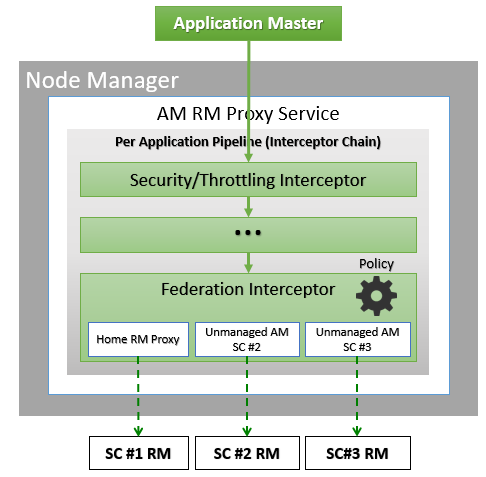
Role of AMRMProxy
Protect the sub-cluster YARN RMs from misbehaving AMs. The AMRMProxy can prevent DDOS attacks by throttling/killing AMs that are asking too many resources.
保护 sub-cluster YARN RMs 不受不良 AMs 的影响。AMRMProxy 可以通过限制/杀死请求过多资源的 AMs 来防止DDO攻击。
Mask the multiple YARN RMs in the cluster, and can transparently allow the AM to span across sub-clusters. All container allocations are done by the YARN RM framework that consists of the AMRMProxy fronting the home and other sub-cluster RMs.
遮掩集群中的多个 YARN RMs ,并透明地(transparently)允许 AM 跨越子群。所有的容器分配都是通过YARN RM 框架完成的,该框架由 home sub-cluster RM 和 other sub-cluster RMs 的 AMRMProxy 组成。
Intercepts all the requests, thus it can enforce application quotas, which would not be enforceable by sub-cluster RM (as each only see a fraction of the AM requests).
截取所有请求,因此它可以强制应用程序配额,而子集群RM将无法强制应用程序配额(因为每个请求只看到AM请求的一部分)。
The AMRMProxy can enforce load-balancing / overflow policies.
AMRMProxy 可以强制执行负载平衡/溢出策略。
Global Policy Generator
Global Policy Generator overlooks the entire federation and ensures that the system is configured and tuned properly all the time. A key design point is that the cluster availability does not depends on an always-on GPG. The GPG operates continuously but out-of-band from all cluster operations, and provide us with a unique vantage point, that allows to enforce global invariants, affect load balancing, trigger draining of sub-clusters that will undergo maintenance, etc. More precisely the GPG will update user capacity allocation-to-subcluster mappings, and more rarely change the policies that run in Routers, AMRMProxy (and possible RMs).
全局策略生成器(Global Policy Generator: GPG)整体把控(overlook)整个联邦系统,并确保系统始终正确配置和调优。一个关键的设计点是集群的可用性并不依赖于一个始终在线的 GPG。**GPG连续运行,但在所有集群的操作都是out-of-band**,并为我们提供了一个独特的优势点,允许强制执行全局不变量、影响负载平衡、触发以下动作:排除要进行维护的子集群等。更准确地说,GPG将更新:用户与分配给子集群的容量之间的映射关系,并且很少更改在路由器、AMRMProxy (以及可能的 RMs)中运行的策略。
In case the GPG is not-available, cluster operations will continue as of the last time the GPG published policies, and while a long-term unavailability might mean some of the desirable properties of balance, optimal cluster utilization and global invariants might drift away, compute and access to data will not be compromised.
如果 GPG 不可用,则集群操作将按照在 GPG 上次发布的策略继续进行,而长期不可用可能意味着平衡、最佳集群利用率和全局不变量的某些理想属性可能会偏移,计算以及访问数据不会被妥协。
NOTE: In the current implementation the GPG is a manual tuning process, simply exposed via a CLI (YARN-3657).
注意:在当前的实现中,GPG 是一个手动调优过程,只需通过 CLI(yarn-3657)公开即可。
This part of the federation system is part of future work in YARN-5597.
联邦系统的这一部分是 YARN-5597 未来工作的一部分。
Federation State-Store
The Federation State defines the additional state that needs to be maintained to loosely couple multiple individual sub-clusters into a single large federated cluster. This includes the following information:
联邦状态( Federation State)定义了需要维护的额外状态,以便将多个子集群松散地耦合到单个大型联邦集群中。这包括以下信息:
1. Sub-cluster Membership
The member YARN RMs continuously heartbeat to the state store to keep alive and publish their current capability/load information. This information is used by the Global Policy Generator (GPG) to make proper policy decisions. Also this information can be used by routers to select the best home sub-cluster. This mechanism allows us to dynamically grow/shrink the “cluster fleet” by adding or removing sub-clusters. This also allows for easy maintenance of each sub-cluster. This is new functionality that needs to be added to the YARN RM but the mechanisms are well understood as it’s similar to individual YARN RM HA.
成员 YARN RMs 发出连续心跳到 State Store来保持激活状态并发布其当前能力值(capability)/负载信息(load information)。全局策略生成器(GPG)使用此信息做出正确的策略决策。路由器也可以利用这些信息来选择最佳的 home sub-cluster。这个机制允许我们通过添加或删除子集群来动态地增长(grow)/收缩(shrink)“集群的机群(cluster fleet)”。这还允许轻松维护每个子集群。这是需要添加到 YARN RM 中的新功能,但机制已被很好地理解,因为它类似于单个 YARN RM HA。
2. Application’s Home Sub-cluster
The sub-cluster on which the Application Master (AM) runs is called the Application’s “home sub-cluster”. The AM is not limited to resources from the home sub-cluster but can also request resources from other sub-clusters, referred to as secondary sub-clusters. The federated environment will be configured and tuned periodically such that when an AM is placed on a sub-cluster, it should be able to find most of the resources on the home sub-cluster. Only in certain cases it should need to ask for resources from other sub-clusters.
运行 Application Master(AM)的子集群称为应用程序的 “home sub-cluster” 。AM不限于来自 home sub-cluster 的资源,还可以从其他子集群(被称为 secondary sub-clusters)请求资源。联邦环境将定期进行配置和调优,这样当 AM 放置在一个子集群上时,它应该能够找到 home sub-cluster 上的大部分资源。只有在某些情况下,它才需要从其他子集群请求资源。
Federation Policy Store
The federation Policy Store is a logically separate store (while it might be backed by the same physical component), which contains information about how applications and resource requests are routed to different sub-clusters. The current implementation provides several policies, ranging from random/hashing/round robin/priority to more sophisticated ones which account for sub-cluster load, and request locality needs.
联邦 Policy Store 是一个逻辑上独立的存储(虽然它可能由同一物理组件支持),其中包含如何将应用程序和资源请求路由到不同子群集的信息。当前的实现提供了几个策略,从随机/哈希/循环/优先级到更复杂的策略,这些策略负责子集群负载和请求位置需求。
Running Applications across Sub-Clusters
When an application is submitted, the system will determine the most appropriate sub-cluster to run the application, which we call as the application’s home sub-cluster. All the communications from the AM to the RM will be proxied via the AMRMProxy running locally on the AM machine. AMRMProxy exposes the same ApplicationMasterService protocol endpoint as the YARN RM. The AM can request containers using the locality information exposed by the storage layer. In ideal case, the application will be placed on a sub-cluster where all the resources and data required by the application will be available, but if it does need containers on nodes in other sub-clusters, AMRMProxy will negotiate with the RMs of those sub-clusters transparently and provide the resources to the application, thereby enabling the application to view the entire federated environment as one massive YARN cluster. AMRMProxy, Global Policy Generator (GPG) and Router work together to make this happen seamlessly.
提交应用程序时,系统将确定运行应用程序的最合适的子集群,我们称之为应用程序的 home sub-cluster。从 AM 到 RM 的所有通信都将通过在 AM 机器上运行的 AMRMProxy 进行代理。 AMRMProxy 开放了相同的 ApplicationMasterService 协议端点作为与 YARN RM。AM可以使用存储层公开的位置信息请求容器。理想情况下,应用程序将被放置在子集群上,应用程序所需的所有资源和数据都将可用,但如果它确实需要其他子集群中节点上的容器, AMRMProxy 将透明地与这些子集群的 RMs 协商,并提供资源。源到应用程序,从而使应用程序能够将整个联邦环境视为一个巨大的 YARN 集群。 AMRMProxy 、全局策略生成器(gpg)和路由器协同工作,实现无缝连接。
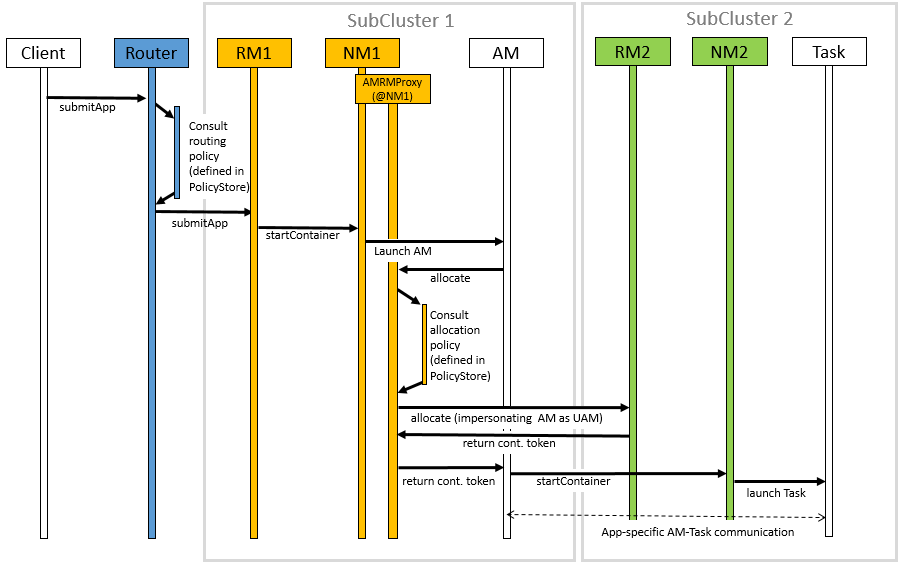
The figure shows a sequence diagram for the following job execution flow:
该图显示了以下作业执行流程的序列图:
The Router receives an application submission request that is complaint to the YARN Application Client Protocol.
路由器接收到一个应用程序提交请求,这是对 YARN 应用客户端协议的投诉。
The router interrogates a routing table / policy to choose the “ “home RM” ” for the job (the policy configuration is received from the state-store on heartbeat).
路由器询问路由表/策略以选择作业的“ “home RM” ”(有心跳的时候,策略配置从状态存储 (state-store) 接收)。
The router queries the membership state to determine the endpoint of the “home RM” .
路由器查询成员身份状态以确定 “home RM” 的端点。
The router then redirects the application submission request to the “home RM” .
然后,路由器将应用程序提交请求重定向到 “home RM” 。
The router updates the application state with the home sub-cluster identifier.
路由器使用 home sub-cluster 标识更新应用程序状态。
Once the application is submitted to the “home RM” , the stock YARN flow is triggered, i.e. the application is added to the scheduler queue and its AM started in the home sub-cluster, on the first NodeManager that has available resources.
一旦应用程序提交到 “home RM” ,库存的 YARN 流就会被触发,即将应用程序添加到调度器队列中,并在home sub-cluster 中具有可用资源的第一个节点管理器(NM) 来启动它的 AM。
a. During this process, the AM environment is modified by indicating that the address of the AMRMProxy as the YARN RM to talk to.
a. 在此过程中,通过指出 AMRMProxy 的地址作为要通信的 YARN RM 来修改 AM 环境(变量)。
b. The security tokens are also modified by the NM when launching the AM, so that the AM can only talk with the AMRMProxy. Any future communication from AM to the YARN RM is mediated by the AMRMProxy.
b.安全令牌(security tokens)在启动AM时也会被NM修改,因此 AM 只能与 AMRMproxy 通信。从 AM 到 YARN RM 的任何未来通信都由 Amrmproxy 做媒。
The AM will then request containers using the locality information exposed by HDFS.
然后,AM 将使用 HDFS 公开的位置信息请求容器。Based on a policy the AMRMProxy can impersonate the AM on other sub-clusters, by submitting an Unmanaged AM, and by forwarding the AM heartbeats to relevant sub-clusters.
根据策略, AMRMProxy 可以通过提交还未被管理的AM(Unmanaged AM)以及将 AM 心跳转发到相关子群集来扮演其他子群集上的 AM。
a. Federation supports multiple application attempts with AMRMProxy HA. AM containers will have different attempt id in home sub-cluster, but the same Unmanaged AM in secondaries will be used across attempts.
a. 联邦支持使用 AMRMProxy HA 进行多个应用程序尝试。AM 容器 在 home sub-cluster 中具有不同的尝试ID,但在不同的尝试之间将使用secondaries中相同的 UAM (Unmanaged AM)。
b. When AMRMProxy HA is enabled, UAM token will be stored in Yarn Registry. In the registerApplicationMaster call of each application attempt, AMRMProxy will go fetch existing UAM tokens from registry (if any) and re-attached to the existing UAMs.
b. 启用 AMRMProxy HA 后,UAM(Unmanaged AM) 令牌将存储在 YARN 注册表中。在每次应用程序尝试的
registerApplicationMaster调用中, AMRMProxy 将从注册表(如果有)中获取现有的UAM令牌,并重新连接到现有的UAM。The AMRMProxy will use both locality information and a pluggable policy configured in the state-store to decide whether to forward the resource requests received by the AM to the Home RM or to one (or more) Secondary RMs. In Figure 1, we show the case in which the AMRMProxy decides to forward the request to the secondary RM.
AMRMProxy 将同时使用位置信息和状态存储(state-store)中配置的可插拔策略来决定是将AM接收到的资源请求转发到 Home RM 还是一个(或多个)Secondary RMs。在图1中,我们展示了 AMRMProxy 决定将请求转发到 secondary RM 的情况。
The secondary RM will provide the AMRMProxy with valid container tokens to start a new container on some node in its sub-cluster. This mechanism ensures that each sub-cluster uses its own security tokens and avoids the need for a cluster wide shared secret to create tokens. The AMRMProxy forwards the allocation response back to the AM.
secondary RM 将向 AMRMProxy 提供有效的容器令牌,以便在其子集群中的某个节点上启动新的容器。此机制确保每个子集群使用自己的安全令牌(security tokens),并避免需要集群范围的共享机密来创建令牌。 AMRMProxy 将分配响应转发回 AM。
- The AM starts the container on the target NodeManager (on sub-cluster 2) using the standard YARN protocols.
AM使用标准 YARN 协议在目标节点管理器(在子集群2)上启动容器。
Configuration
To configure the YARN to use the Federation, set the following property in the conf/yarn-site.xml:
要将 YARN 配置为使用 Federation,请在 conf/yarn-site.xml 中设置以下属性:
EVERYWHERE:
These are common configurations that should appear in the conf/yarn-site.xml at each machine in the federation.
这些是常见的配置,应该出现在联邦中每台机器的 conf/yarn-site.xml 中。
| Property | Example | Description |
|---|---|---|
yarn.federation.enabled |
true |
Whether federation is enabled or not 是否启用联邦机制 |
yarn.resourcemanager.cluster-id |
<unique-subcluster-id> |
The unique subcluster identifier for this RM (same as the one used for HA). 为这个 RM 使用子集群的标识符(HA模式下,互为备份的 RM 也是同样的配置) |
State-Store:
Currently, we support ZooKeeper and SQL based implementations of the state-store.
目前,我们支持状态存储的ZooKeeper和基于SQL的实现。
Note: The State-Store implementation must always be overwritten with one of the below.
注意:状态存储实现必须始终被下面的某个覆盖。
ZooKeeper: one must set the ZooKeeper settings for Hadoop:
动物园管理员:必须为Hadoop设置 ZooKeeper:
| Property | Example | Description |
|---|---|---|
yarn.federation.state-store.class |
org.apache.hadoop.yarn.<br />server.federation.store.<br />impl.ZookeeperFederationStateStore |
The type of state-store to use. |
hadoop.zk.address |
host:port |
The address for the ZooKeeper ensemble. |
SQL: one must setup the following parameters:
SQL: 必须设置以下参数:
| Property | Example | Description |
|---|---|---|
yarn.federation.state-store.class |
org.apache.hadoop.yarn.server.federation.store.impl.SQLFederationStateStore |
The type of state-store to use. |
yarn.federation.state-store.sql.url |
jdbc:mysql://<host>:<port>/FederationStateStore |
For SQLFederationStateStore the name of the DB where the state is stored. |
yarn.federation.state-store.sql.jdbc-class |
com.mysql.jdbc.jdbc2.optional.MysqlDataSource |
For SQLFederationStateStore the jdbc class to use. |
yarn.federation.state-store.sql.username |
<dbuser> |
For SQLFederationStateStore the username for the DB connection. |
yarn.federation.state-store.sql.password |
<dbpass> |
For SQLFederationStateStore the password for the DB connection. |
We provide scripts for MySQL and Microsoft SQL Server.
我们为MySQL和Microsoft SQL Server提供脚本。
For MySQL, one must download the latest jar version 5.x from MVN Repository and add it to the CLASSPATH. Then the DB schema is created by executing the following SQL scripts in the database:
对于MySQL,必须从MVN存储库下载最新的JAR5.x版本,并将其添加到类路径。然后,通过在数据库中执行以下SQL脚本来创建 DB schema:
sbin/FederationStateStore/MySQL/FederationStateStoreDatabase.sqlsbin/FederationStateStore/MySQL/FederationStateStoreUser.sqlsbin/FederationStateStore/MySQL/FederationStateStoreTables.sqlsbin/FederationStateStore/MySQL/FederationStateStoreStoredProcs.sql
In the same directory we provide scripts to drop the Stored Procedures, the Tables, the User and the Database.
在同一个目录中,我们提供了删除存储过程、表、用户和数据库的脚本。
Note: the defines a default user/password for the DB that you are highly encouraged to set this to a proper strong password.
注意:FederationStateStoreUser.sql 定义了数据库的默认用户/密码,强烈建议您将其设置为正确的强密码。
For SQL-Server, the process is similar, but the jdbc driver is already included. SQL-Server scripts are located in sbin/FederationStateStore/SQLServer/.
对于SQL Server,过程类似,但已经包含了JDBC驱动程序。SQL Server脚本位于sbin/federationstatestore/sql server/中。
Optional:
| Property | Example | Description |
|---|---|---|
yarn.federation.failover.enabled |
true |
Whether should retry considering RM failover within each subcluster. 考虑到每个子群集中的RM故障转移,是否应重试。 |
yarn.federation.blacklist-subclusters |
<subcluster-id> |
A list of black-listed sub-clusters, useful to disable a sub-cluster 黑名单子群集的列表,用于关闭子集群 |
yarn.federation.policy-manager |
org.apache.hadoop.yarn.<br />server.federation.policies.<br />manager.<br />WeightedLocalityPolicyManager |
The choice of policy manager determines how Applications and ResourceRequests are routed through the system. 策略管理器的选择决定了应用程序和资源请求在系统中的路由方式。 |
yarn.federation.policy-manager-params |
<binary> |
The payload that configures the policy. In our example a set of weights for router and amrmproxy policies. This is typically generated by serializing a policymanager that has been configured programmatically, or by populating the state-store with the .json serialized form of it. 配置策略的有效负载。在我们的示例中,路由器和 AMRMProxy 策略的一组权重。这通常是通过序列化已通过编程方式配置的 PolicyManager 或使用.json序列化形式填充状态存储来生成的。 |
yarn.federation.subcluster-resolver.class |
org.apache.hadoop.<br />yarn.server.federation.<br />resolver.<br />DefaultSubClusterResolverImpl |
The class used to resolve which subcluster a node belongs to, and which subcluster(s) a rack belongs to. 用于解析节点所属的子群集和机架所属的子群集的类。 |
yarn.federation.machine-list |
node1,subcluster1,rack1\n<br /> node2 , subcluster2, RACK1\n<br /> node3,subcluster3, rack2\n<br /> node4, subcluster3, rack2\n |
a list of Nodes, Sub-clusters, Rack, used by the DefaultSubClusterResolverImpl默认子集群使用的节点、子群集、机架列表。 |
ON RMs:
These are extra configurations that should appear in the conf/yarn-site.xml at each ResourceManager.
这些是额外的配置,应该出现在每个资源管理器的conf/yarn-site.xml中。
| Property | Example | Description |
|---|---|---|
yarn.resourcemanager.epoch |
<unique-epoch> |
The seed value for the epoch. This is used to guarantee uniqueness of container-IDs generate by different RMs. It must therefore be unique among sub-clusters and well-spaced to allow for failures which increment epoch. Increments of 1000 allow for a large number of sub-clusters and practically ensure near-zero chance of collisions (a clash will only happen if a container is still alive for 1000 restarts of one RM, while the next RM never restarted, and an app requests more containers). epoch的种子值。这是为了保证不同 RMs 生成的容器ID的唯一性。因此,它在子集群中必须是唯一的,并且具有良好的间隔以允许增加epoch出现的失败。增量1000允许大量的子集群,并且实际上可以确保几乎没有发生冲突的机会(只有当容器在1000次重新启动一个 RM 时仍处于活动状态,而下一个 RM 从未重新启动,并且应用程序请求更多容器时,才会发生冲突)。 |
Optional:
| Property | Example | Description |
|---|---|---|
yarn.federation.state-store.heartbeat-interval-secs |
60 |
The rate at which RMs report their membership to the federation to the central state-store. RMs 向中央状态存储报告其联盟成员身份的时间间隔。 |
ON ROUTER:
These are extra configurations that should appear in the conf/yarn-site.xml at each Router.
这些是额外的配置,应该出现在每个路由器的 conf/yarn-site.xml 中。
| Property | Example | Description |
|---|---|---|
yarn.router.bind-host |
0.0.0.0 |
Host IP to bind the router to. The actual address the server will bind to. If this optional address is set, the RPC and webapp servers will bind to this address and the port specified in yarn.router.*.address respectively. This is most useful for making Router listen to all interfaces by setting to 0.0.0.0.路由器绑定的主机IP。服务器将绑定到的实际地址。如果设置了此可选地址,则 RPC 和 webapp 服务器将分别绑定到此地址和 yarn.router.*.address 中指定的端口。这对于通过设置为0.0.0.0将路由器列表设置为所有接口最有用。 |
yarn.router.clientrm.<br />interceptor-class.pipeline |
org.apache.hadoop.yarn.<br />server.router.clientrm.<br />FederationClientInterceptor |
A comma-seperated list of interceptor classes to be run at the router when interfacing with the client. The last step of this pipeline must be the Federation Client Interceptor. 与客户端接口交互时要在路由器上运行的截断类的逗号分隔列表。此管道的最后一步必须是Federation Client拦截器。 |
Optional:
| Property | Example | Description |
|---|---|---|
yarn.router.hostname |
0.0.0.0 |
Router host name. |
yarn.router.clientrm.address |
0.0.0.0:8050 |
路由主机名 |
yarn.router.webapp.address |
0.0.0.0:8089 |
Webapp address at the router. webapp在路由器的地址 |
yarn.router.admin.address |
0.0.0.0:8052 |
Admin address at the router. 路由器的管理地址 |
yarn.router.webapp.https.address |
0.0.0.0:8091 |
Secure webapp address at the router. 在路由器上安全的webapp地址 |
yarn.router.submit.retry |
3 |
The number of retries in the router before we give up. 在放弃之前,在路由器上的尝试次数。 |
yarn.federation.statestore.max-connections |
10 |
This is the maximum number of parallel connections each Router makes to the state-store. 每个路由器连接到state-store的最大并发数 |
yarn.federation.cache-ttl.secs |
60 |
The Router caches informations, and this is the time to leave before the cache is invalidated. 路由器缓存信息,这是缓存的有效时间。 |
yarn.router.webapp.<br />interceptor-class.pipeline |
org.apache.hadoop.yarn.<br />server.router.webapp.<br />FederationInterceptorREST |
A comma-seperated list of interceptor classes to be run at the router when interfacing with the client via REST interface. The last step of this pipeline must be the Federation Interceptor REST. 当通过 REST 接口与客户机交互时,要在路由器上运行的拦截器类的逗号分隔列表。此管道的最后一步必须是 Federation Interceptor REST 。 |
ON NMs:
These are extra configurations that should appear in the conf/yarn-site.xml at each NodeManager.
这些额外的配置应该出现在每个节点管理器的 conf/yarn-site.xml 中。
| Property | Example | Description |
|---|---|---|
yarn.nodemanager.<br />amrmproxy.enabled |
true |
Whether or not the AMRMProxy is enabled. 是否启用 AMRMProxy |
yarn.nodemanager.amrmproxy.<br />interceptor-class.pipeline |
org.apache.hadoop.yarn.<br />server.nodemanager.amrmproxy.<br />FederationInterceptor |
A comma-separated list of interceptors to be run at the amrmproxy. For federation the last step in the pipeline should be the FederationInterceptor. 要在 AMRMProxy 上运行的拦截器的逗号分隔列表。对于联邦,管道中的最后一步应该是联合拦截器。 |
yarn.client.<br />failover-proxy-provider |
org.apache.hadoop.yarn.<br />server.federation.failover<br />.FederationRMFailoverProxyProvider |
The class used to connect to the RMs by looking up the membership information in federation state-store. This must be set if federation is enabled, even if RM HA is not enabled. 通过在联邦 state-store 中查找成员身份信息来连接到 RMs的类。如果启用了联邦,即使未启用RM HA,也必须设置此选项。 |
Optional:
| Property | Example | Description |
|---|---|---|
yarn.nodemanager.amrmproxy.ha.enable |
true |
Whether or not the AMRMProxy HA is enabled for multiple application attempt suppport. 是否为多个应用程序尝试支持启用 AMRMProxy HA。 |
yarn.federation.statestore.max-connections |
1 |
The maximum number of parallel connections from each AMRMProxy to the state-store. This value is typically lower than the router one, since we have many AMRMProxy that could burn-through many DB connections quickly. 从每个 AMRMProxy 到状态存储的最大并行连接数。这个值通常低于Router在这个属性的值,因为我们有许多 AMRMProxy 可以快速通过许多 DB 连接。 |
yarn.federation.cache-ttl.secs |
300 |
The time to leave for the AMRMProxy cache. Typically larger than at the router, as the number of AMRMProxy is large, and we want to limit the load to the centralized state-store. 离开 Amrmproxy 缓存的时间。通常比 Router在这个属性上设置的值要大,因为AMRMProxy 的数量很大,我们希望将负载限制到集中式状态存储。 |
Running a Sample Job
In order to submit jobs to a Federation cluster one must create a seperate set of configs for the client from which jobs will be submitted. In these, the conf/yarn-site.xml should have the following additional configurations:
为了将作业提交到联邦集群,必须为将从中提交作业的客户端创建一组单独的配置。在这些配置中,conf/yarn-site.xml 应该具有以下附加配置:
| Property | Example | Description |
|---|---|---|
yarn.resourcemanager.address |
<router_host>:8050 |
Redirects jobs launched at the client to the router’s client RM port. 将在客户端启动的作业重定向到路由器的客户端 RM 端口。 |
yarn.resourcemanger.scheduler.address |
localhost:8049 |
Redirects jobs to the federation AMRMProxy port. 将作业重定向到联邦的AMRMProxy 端口 |
Any YARN jobs for the cluster can be submitted from the client configurations described above. In order to launch a job through federation, first start up all the clusters involved in the federation as described here. Next, start up the router on the router machine with the following command:
集群的任何 YARN job 都可以从上面描述的客户机配置提交。为了通过联邦启动一个作业,首先启动联邦中涉及的所有集群,如本文所述。接下来,使用以下命令在路由器计算机上启动路由器:
1 | $HADOOP_HOME/bin/yarn --daemon start router |
Now with $HADOOP_CONF_DIR pointing to the client configurations folder that is described above, run your job the usual way. The configurations in the client configurations folder described above will direct the job to the router’s client RM port where the router should be listening after being started. Here is an example run of a Pi job on a federation cluster from the client:
现在,当 $HADOOP_CONF_DIR 指向上面描述的客户端配置文件夹时,以通常的方式运行您的作业。上面描述的客户端配置文件夹中的配置将把作业引导到路由器的客户端 RM 端口,路由器在启动后应该在该端口上进行侦听。下面是从客户端在联邦集群上运行 Pi 作业的示例:
1 | $HADOOP_HOME/bin/yarn jar hadoop-mapreduce-examples-3.0.0.jar pi 16 1000 |
This job is submitted to the router which as described above, uses a generated policy from the GPG to pick a home RM for the job to which it is submitted.
此作业将提交给路由器,如上文所述,路由器使用GPG生成的策略为其提交到的作业选择一个 Home RM。
The output from this particular example job should be something like:
这个特定示例作业的输出应该类似于:
1 | 2017-07-13 16:29:25,055 INFO mapreduce.Job: Job job_1499988226739_0001 running in uber mode : false |
The state of the job can also be tracked on the Router Web UI at routerhost:8089. Note that no change in the code or recompilation of the input jar was required to use federation. Also, the output of this job is the exact same as it would be when run without federation. Also, in order to get the full benefit of federation, use a large enough number of mappers such that more than one cluster is required. That number happens to be 16 in the case of the above example.
作业的状态也可以在路由器 Web UI 上的 routerhost:8089上跟踪。注意,使用联邦不需要更改代码或重新编译输入的jar包。此外,此作业的输出与在没有联合的情况下运行时的输出完全相同。此外,为了充分利用联合,请使用足够多的映射器,以便多个集群的需求。在上面的例子中,这个数字恰好是16。
A list of References
- 官方关于 YARN Federation issue: https://issues.apache.org/jira/browse/YARN-2915
- HDFS基于路由的Federation方案
- YARN Federation的架构设计
