注:翻译时,最新Spark 2.0.0系列最新发行版是:2.4.5
Overview
Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. You can express your streaming computation the same way you would express a batch computation on static data. The Spark SQL engine will take care of running it incrementally and continuously and updating the final result as streaming data continues to arrive. You can use the Dataset/DataFrame API in Scala, Java, Python or R to express streaming aggregations, event-time windows, stream-to-batch joins, etc. The computation is executed on the same optimized Spark SQL engine. Finally, the system ensures end-to-end exactly-once fault-tolerance guarantees through checkpointing and Write-Ahead Logs. In short, Structured Streaming provides fast, scalable, fault-tolerant, end-to-end exactly-once stream processing without the user having to reason about streaming.
结构化流是一个基于Spark SQL引擎的可扩展、容错的流处理引擎。您可以用在静态数据上表示批处理计算的方式来表示流计算。Spark SQL引擎将负责递增和连续地运行它,并在流数据继续到达时更新最终结果。可以使用Scala、Java、Python 或 R 中的 DataSet/DataFrame API来表示流聚合、事件时间窗口、流到批连接等。在相同的优化 Spark SQL 引擎上执行计算。最后,系统通过检查点和提前写入日志来确保端到端的容错性。简而言之,结构化流提供了快速、可扩展、容错、端到端的一次性流处理,而用户无需考虑流。
Internally, by default, Structured Streaming queries are processed using a micro-batch processing engine, which processes data streams as a series of small batch jobs thereby achieving end-to-end latencies as low as 100 milliseconds and exactly-once fault-tolerance guarantees. However, since Spark 2.3, we have introduced a new low-latency processing mode called Continuous Processing, which can achieve end-to-end latencies as low as 1 millisecond with at-least-once guarantees. Without changing the Dataset/DataFrame operations in your queries, you will be able to choose the mode based on your application requirements.
在内部,默认情况下,结构化流式查询使用微批处理引擎进行处理,该引擎将数据流作为一系列小批处理作业进行处理,从而实现端到端的延迟,最短可达100毫秒,并且完全可以保证一次容错。然而,自Spark 2.3以来,我们引入了一种新的低延迟处理模式,称为连续处理( Continuous Processing),它可以在至少一次保证的情况下实现低至1毫秒的端到端延迟。在查询中不更改 Dataset/DataFrame 操作的情况下,您可以根据应用程序要求选择模式。
In this guide, we are going to walk you through the programming model and the APIs. We are going to explain the concepts mostly using the default micro-batch processing model, and then later discuss Continuous Processing model. First, let’s start with a simple example of a Structured Streaming query - a streaming word count.
在本指南中,我们将向您介绍编程模型和API。我们将主要使用默认的微批量处理模型来解释这些概念,然后讨论连续处理(Continuous Processing)模型。首先,让我们从一个简单的结构化流式查询示例开始——流式字数。
Quick Example
快速示例
Let’s say you want to maintain a running word count of text data received from a data server listening on a TCP socket. Let’s see how you can express this using Structured Streaming. You can see the full code in Scala/Java/Python/R. And if you download Spark, you can directly run the example. In any case, let’s walk through the example step-by-step and understand how it works. First, we have to import the necessary classes and create a local SparkSession, the starting point of all functionalities related to Spark.
假设您希望维护从侦听TCP套接字的数据服务器接收的文本数据的运行 word count。让我们看看如何使用结构化流来表达这一点。您可以在Scala/Java/Python /R中看到完整的代码,如果下载 Spark,则可以直接运行该示例。在任何情况下,让我们一步一步地浏览这个示例,并了解它是如何工作的。首先,我们必须导入必要的类并创建本地 SparkSession,这是与 Spark 相关的所有功能的起点。
1 | import org.apache.spark.sql.functions._ |
Next, let’s create a streaming DataFrame that represents text data received from a server listening on localhost:9999, and transform the DataFrame to calculate word counts.
接下来,让我们创建一个流式数据帧,它表示从侦听 localhost:9999 的服务器接收到的文本数据,并转换该数据帧以计算字数。
1 | // Create DataFrame representing the stream of input lines from connection to localhost:9999 |
This lines DataFrame represents an unbounded table containing the streaming text data. This table contains one column of strings named “value”, and each line in the streaming text data becomes a row in the table. Note, that this is not currently receiving any data as we are just setting up the transformation, and have not yet started it. Next, we have converted the DataFrame to a Dataset of String using .as[String], so that we can apply the flatMap operation to split each line into multiple words. The resultant words Dataset contains all the words. Finally, we have defined the wordCounts DataFrame by grouping by the unique values in the Dataset and counting them. Note that this is a streaming DataFrame which represents the running word counts of the stream.
此行数据帧表示包含流式文本数据的无边界表。此表包含一列名为“value”的字符串,流式文本数据中的每一行将成为表中的一行。注意,由于我们只是在设置转换,所以目前还没有接收到任何数据,而且还没有启动转换。接下来,我们使用 .as[string] 将 DataFrame 转换为字符串 Dataset ,这样我们就可以应用 flatMap 操作将每一行拆分为多个字。结果 words Dataset 包含所有单词。最后,我们通过对数据集中的唯一值进行分组并对其进行计数来定义 wordCounts DataFrame。注意,这是一个流数据帧,它表示流的运行字数。
We have now set up the query on the streaming data. All that is left is to actually start receiving data and computing the counts. To do this, we set it up to print the complete set of counts (specified by outputMode("complete")) to the console every time they are updated. And then start the streaming computation using start().
我们现在已经设置了对流数据的查询。剩下的就是实际开始接收数据并计算计数。为此,我们将其设置为每次更新时向控制台打印完整的计数集(由 outputmode(“complete”) 指定)。然后使用 start() 启动流计算。
1 | // Start running the query that prints the running counts to the console |
After this code is executed, the streaming computation will have started in the background. The query object is a handle to that active streaming query, and we have decided to wait for the termination of the query using awaitTermination() to prevent the process from exiting while the query is active.
执行此代码后,流计算将在后台启动。查询对象是该活动流查询的句柄,我们决定使用 awaitTermination() 等待查询终止,以防止在查询激活时进程退出。
To actually execute this example code, you can either compile the code in your own Spark application, or simply run the example once you have downloaded Spark. We are showing the latter. You will first need to run Netcat (a small utility found in most Unix-like systems) as a data server by using
要实际执行这个示例代码,您可以在自己的 Spark应用程序中编译代码,也可以在下载了spark之后简单地运行这个示例。我们正在展示后者。您首先需要使用:
1 | nc -lk 9999 |
Then, in a different terminal, you can start the example by using
然后,在另一个终端中,可以使用
1 | ./bin/run-example org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount localhost 9999 |
Then, any lines typed in the terminal running the netcat server will be counted and printed on screen every second. It will look something like the following.
然后,在运行 netcat 服务器的终端中键入的任何行都将被计数并每秒在屏幕上打印。它看起来像下面这样。
1 | 终端 1: 运行 Netcat |
Scala代码
1 | 终端 2: 运行 StructuredNetworkWordCount |
Java代码
1 | 终端 2: 运行 StructuredNetworkWordCount |
Python代码
1 | 终端 2: 运行 StructuredNetworkWordCount |
R代码
1 | 终端 2: 运行 structured_network_wordcount.R |
上面的结果:
1 |
|
Programming Model
编程模型
The key idea in Structured Streaming is to treat a live data stream as a table that is being continuously appended. This leads to a new stream processing model that is very similar to a batch processing model. You will express your streaming computation as standard batch-like query as on a static table, and Spark runs it as an incremental query on the unbounded input table. Let’s understand this model in more detail.
结构化流中的关键思想是将实时数据流视为一个不断追加的表。这导致了一个新的流处理模型,与批处理模型非常相似。您将把流计算表示为与静态表类似的标准批处理查询,Spark将在无边界输入表上以增量查询的形式运行它。让我们更详细地了解这个模型。
Basic Concepts
基本概念
Consider the input data stream as the “Input Table”. Every data item that is arriving on the stream is like a new row being appended to the Input Table.
将输入数据流视为“输入表”。到达流中的每个数据项都像是追加到输入表中的新行。
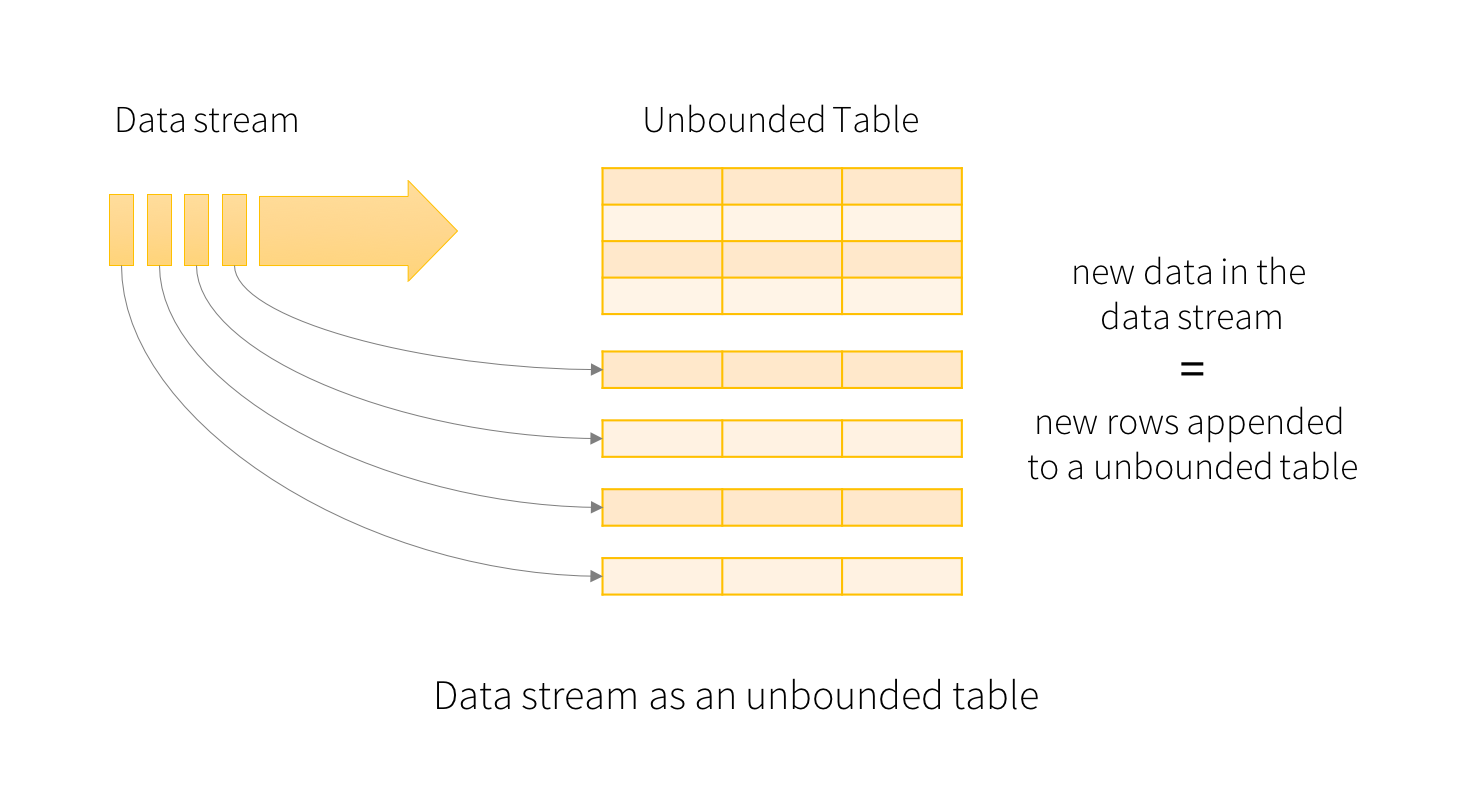
A query on the input will generate the “Result Table”. Every trigger interval (say, every 1 second), new rows get appended to the Input Table, which eventually updates the Result Table. Whenever the result table gets updated, we would want to write the changed result rows to an external sink.
对输入的查询将生成“结果表”。每一个触发间隔(比如说,每1秒),新的行都会附加到输入表中,这最终会更新结果表。每当结果表更新时,我们都希望将更改后的结果行写入外部接收器。
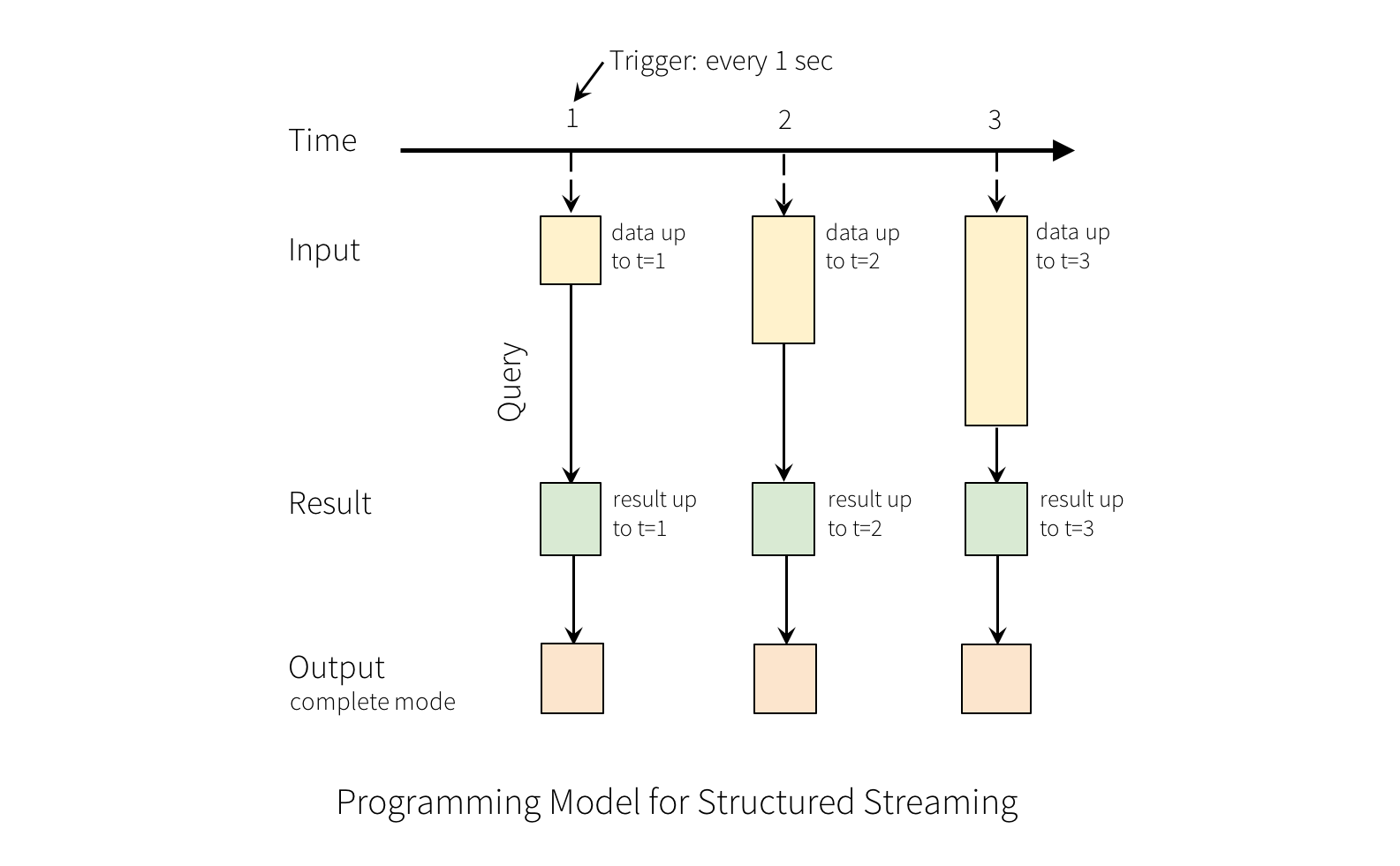
The “Output” is defined as what gets written out to the external storage. The output can be defined in a different mode :
“输出”定义为写入外部存储器的内容。可以在不同的模式下定义输出:
Complete Mode - The entire updated Result Table will be written to the external storage. It is up to the storage connector to decide how to handle writing of the entire table.
完成模式——整个更新的结果表将写入外部存储器。由存储连接器决定如何处理整个表的写入。
Append Mode - Only the new rows appended in the Result Table since the last trigger will be written to the external storage. This is applicable only on the queries where existing rows in the Result Table are not expected to change.
追加模式——只有自上一个触发器以来追加到结果表中的新行才会写入外部存储器。这仅适用于结果表中不希望更改现有行的查询。
Update Mode - Only the rows that were updated in the Result Table since the last trigger will be written to the external storage (available since Spark 2.1.1). Note that this is different from the Complete Mode in that this mode only outputs the rows that have changed since the last trigger. If the query doesn’t contain aggregations, it will be equivalent to Append mode.
更新模式——只有自上次触发器以来在结果表中更新的行才会写入外部存储器(从spark 2.1.1开始可用)。请注意,这与完整模式不同,因为此模式只输出自上一个触发器以来已更改的行。如果查询不包含聚合,则等同于追加模式。
Note that each mode is applicable on certain types of queries. This is discussed in detail later.
请注意,每个模式都适用于某些类型的查询。这将在后面详细讨论。
To illustrate the use of this model, let’s understand the model in context of the Quick Example above. The first lines DataFrame is the input table, and the final wordCounts DataFrame is the result table. Note that the query on streaming lines DataFrame to generate wordCounts is exactly the same as it would be a static DataFrame. However, when this query is started, Spark will continuously check for new data from the socket connection. If there is new data, Spark will run an “incremental” query that combines the previous running counts with the new data to compute updated counts, as shown below.
为了说明这个模型的使用,让我们在上面的快速示例的上下文中理解这个模型。第一行数据框是输入表,最后一行字数数据框是结果表。请注意,在流式处理行 DataFrame 上生成字计数的查询与静态 DataFrame 的查询完全相同。但是,当这个查询启动时,Spark 将不断检查来自套接字连接的新数据。如果有新的数据,Spark将运行一个“增量”查询,将以前运行的计数与新的数据结合起来,以计算更新的计数,如下所示。
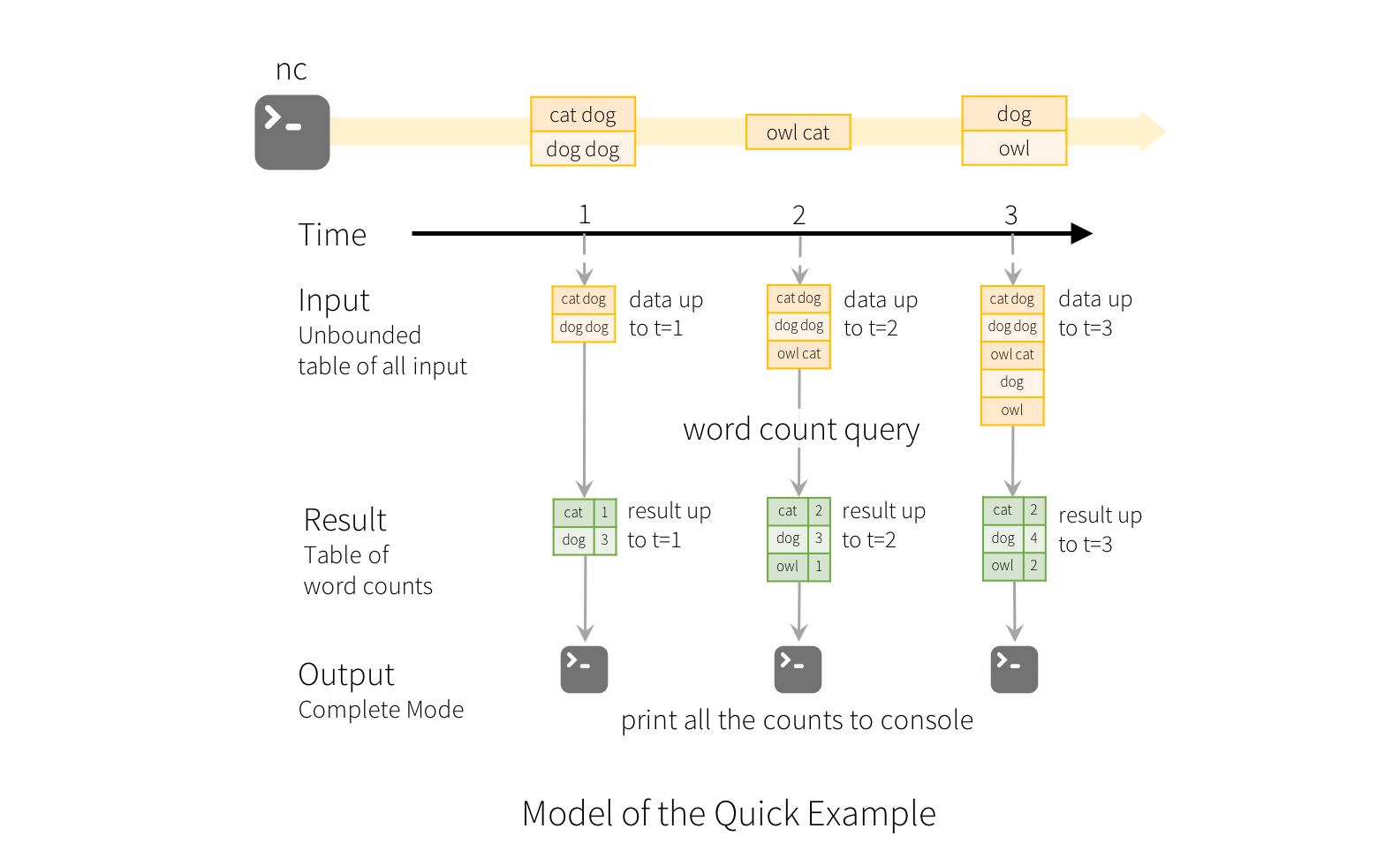
Note that Structured Streaming does not materialize the entire table. It reads the latest available data from the streaming data source, processes it incrementally to update the result, and then discards the source data. It only keeps around the minimal intermediate state data as required to update the result (e.g. intermediate counts in the earlier example) .
请注意,结构化流并没有实现整个表。它从流数据源中读取最新的可用数据,然后递增处理以更新结果,然后丢弃源数据。它只保留更新结果所需的最小中间状态数据(例如前面示例中的中间计数)。
This model is significantly different from many other stream processing engines. Many streaming systems require the user to maintain running aggregations themselves, thus having to reason about fault-tolerance, and data consistency (at-least-once, or at-most-once, or exactly-once). In this model, Spark is responsible for updating the Result Table when there is new data, thus relieving the users from reasoning about it. As an example, let’s see how this model handles event-time based processing and late arriving data.
此模型与许多其他流处理引擎显著不同。许多流系统要求用户自己维护正在运行的聚合,因此必须考虑容错性和数据一致性(至少一次、最多一次或完全一次)。在这个模型中,Spark 负责在有新数据时更新结果表,从而减少用户对结果表的推理。作为一个例子,让我们看看这个模型如何处理基于事件时间的处理和延迟到达的数据。
Handling Event-time and Late Data
处理事件时间和延迟数据
Event-time is the time embedded in the data itself. For many applications, you may want to operate on this event-time. For example, if you want to get the number of events generated by IoT devices every minute, then you probably want to use the time when the data was generated (that is, event-time in the data), rather than the time Spark receives them. This event-time is very naturally expressed in this model – each event from the devices is a row in the table, and event-time is a column value in the row. This allows window-based aggregations (e.g. number of events every minute) to be just a special type of grouping and aggregation on the event-time column – each time window is a group and each row can belong to multiple windows/groups. Therefore, such event-time-window-based aggregation queries can be defined consistently on both a static dataset (e.g. from collected device events logs) as well as on a data stream, making the life of the user much easier.
事件时间是嵌入到数据本身中的时间。对于许多应用程序,您可能希望在此事件时间上进行操作。例如,如果您希望获得每分钟由物联网设备生成的事件数,那么您可能希望使用生成数据的时间(即数据中的事件时间),而不是Spark接收数据的时间。这个事件时间很自然地用这个模型表示——设备中的每个事件都是表中的一行,而事件时间是行中的一列值。这允许基于窗口的聚合(例如,每分钟事件数)只是事件时间列上特殊类型的分组和聚合-每个时间窗口都是一个组,并且每一行可以属于多个窗口/组。因此,这种基于事件时间窗口的聚合查询既可以在静态数据集(例如,从收集的设备事件日志中)上定义,也可以在数据流上定义,从而使用户的生活更加容易。
Furthermore, this model naturally handles data that has arrived later than expected based on its event-time. Since Spark is updating the Result Table, it has full control over updating old aggregates when there is late data, as well as cleaning up old aggregates to limit the size of intermediate state data. Since Spark 2.1, we have support for watermarking which allows the user to specify the threshold of late data, and allows the engine to accordingly clean up old state. These are explained later in more detail in the Window Operations section.
此外,该模型根据事件时间自然地处理比预期晚到达的数据。由于 Spark 正在更新结果表,因此它可以完全控制在有延迟数据时更新旧聚合,以及清除旧聚合以限制中间状态数据的大小。自Spark2.1以来,我们支持水印技术,允许用户指定延迟数据的阈值,并允许引擎相应地清除旧状态。稍后将在窗口操作部分中更详细地解释这些内容。
Fault Tolerance Semantics
容错语义
Delivering end-to-end exactly-once semantics was one of key goals behind the design of Structured Streaming. To achieve that, we have designed the Structured Streaming sources, the sinks and the execution engine to reliably track the exact progress of the processing so that it can handle any kind of failure by restarting and/or reprocessing. Every streaming source is assumed to have offsets (similar to Kafka offsets, or Kinesis sequence numbers) to track the read position in the stream. The engine uses checkpointing and write-ahead logs to record the offset range of the data being processed in each trigger. The streaming sinks are designed to be idempotent for handling reprocessing. Together, using replayable sources and idempotent sinks, Structured Streaming can ensure end-to-end exactly-once semantics under any failure.
只交付一次端到端语义是结构化流设计背后的关键目标之一。为了实现这一点,我们设计了 Structured Streaming 源、接收器和执行引擎,以便可靠地跟踪处理的确切进度,以便通过重新启动和/或重新处理来处理任何类型的故障。假设每个流源都有偏移量(类似于 Kafka 偏移量或 Kinesis 序列号),以跟踪流中的读取位置。引擎使用检查点和提前写入日志来记录每个触发器中正在处理的数据的偏移范围。流式接收器设计成与解决重新处理过程是幂等的。同时,使用可重放源和幂等的接收器,结构化流可以确保在任何故障下端到端的语义都是一次性的。
API using Datasets and DataFrames
使用数据集和数据帧的API
Since Spark 2.0, DataFrames and Datasets can represent static, bounded data, as well as streaming, unbounded data. Similar to static Datasets/DataFrames, you can use the common entry point SparkSession (Scala/Java/Python/R docs) to create streaming DataFrames/Datasets from streaming sources, and apply the same operations on them as static DataFrames/Datasets. If you are not familiar with Datasets/DataFrames, you are strongly advised to familiarize yourself with them using the DataFrame/Dataset Programming Guide.
由于Spark 2.0,DataFrames 和 Datasets 可以表示静态的有界数据,也可以表示流式的无界数据。与静态 Datasets/DataFrames 类似,您可以使用公共入口点 SparkSession(Scala/Java/Python /R文档)从流源创建流DataFrames/Datasets,并将它们作为静态数据流/数据集应用于相同的操作。如果您不熟悉 DataFrames/Datasets,强烈建议您使用《DataFrame/Dataset 编程指南》熟悉它们。
Creating streaming DataFrames and streaming Datasets
创建流式数据帧和流式数据集
Streaming DataFrames can be created through the DataStreamReader interface (Scala/Java/Python docs) returned by SparkSession.readStream(). In R, with the read.stream() method. Similar to the read interface for creating static DataFrame, you can specify the details of the source – data format, schema, options, etc.
Streaming DataFrames 可以通过 SparkSession.readStream() 返回的 DataStreamReader 接口(Scala/Java/Python文档)创建。在 R 中,使用 read.stream() 方法。与创建静态 DataFrame 的读取接口类似,您可以指定源的详细信息—数据格式、模式、选项等。
Input Sources
输入源
There are a few built-in sources. 有一些内置资源。
File source - Reads files written in a directory as a stream of data. Supported file formats are text, csv, json, orc, parquet. See the docs of the
DataStreamReaderinterface for a more up-to-date list, and supported options for each file format. Note that the files must be atomically placed in the given directory, which in most file systems, can be achieved by file move operations.文件源——读取以数据流形式写入目录的文件。支持的文件格式有 text、csv、json、orc、parquet。请参阅
DatastreamReader界面的文档以获取更新的列表,以及每个文件格式支持的选项。注意,文件必须原子地放置在给定的目录中,在大多数文件系统中,可以通过文件移动操作来实现。Kafka source - Reads data from Kafka. It’s compatible with Kafka broker versions 0.10.0 or higher. See the Kafka Integration Guide for more details.
Kafka源——从 Kafka 读取数据。它与 Kafka 经纪人 0.10.0 或更高版本兼容。有关详细信息,请参阅《Kafka集成指南》。
Socket source (for testing) - Reads UTF8 text data from a socket connection. The listening server socket is at the driver. Note that this should be used only for testing as this does not provide end-to-end fault-tolerance guarantees.
套接字源(用于测试)—— 从套接字连接读取utf8文本数据。侦听服务器套接字位于驱动程序处。请注意,这只能用于测试,因为这不提供端到端的容错保证。
Rate source (for testing) - Generates data at the specified number of rows per second, each output row contains a
timestampandvalue. Wheretimestampis aTimestamptype containing the time of message dispatch, andvalueis ofLongtype containing the message count, starting from 0 as the first row. This source is intended for testing and benchmarking.速率源(用于测试)——以每秒指定的行数生成数据,每个输出行包含时间戳和值。其中timestamp是包含消息调度时间的timestamp类型,value是包含消息计数的long类型,从0开始作为第一行。此源用于测试和基准测试。
Some sources are not fault-tolerant because they do not guarantee that data can be replayed using checkpointed offsets after a failure. See the earlier section on fault-tolerance semantics. Here are the details of all the sources in Spark.
有些源不具有容错性,因为它们不能保证在失败后可以使用检查点偏移量重播数据。请参见前面关于容错语义的部分。以下是Spark中所有来源的详细信息。
| Source | Options | Fault-tolerant | Notes |
|---|---|---|---|
| File source | path: path to the input directory, and common to all file formats. maxFilesPerTrigger: maximum number of new files to be considered in every trigger (default: no max) latestFirst: whether to process the latest new files first, useful when there is a large backlog of files (default: false) fileNameOnly: whether to check new files based on only the filename instead of on the full path (default: false). With this set to true, the following files would be considered as the same file, because their filenames, “dataset.txt”, are the same: “file:///dataset.txt” “s3://a/dataset.txt” “s3n://a/b/dataset.txt” “s3a://a/b/c/dataset.txt” For file-format-specific options, see the related methods in DataStreamReader(Scala/Java/Python/R). E.g. for “parquet” format options see DataStreamReader.parquet(). In addition, there are session configurations that affect certain file-formats. See the SQL Programming Guide for more details. E.g., for “parquet”, see Parquet configuration section.路径:输入目录的路径,所有文件格式的通用路径。 maxFilesperTrigger : 每个触发器中要考虑的新文件的最大数目(默认值:no max)latestFirst : 是否首先处理最新的新文件,当有大量文件积压时很有用(默认值:false)fileNameOnly : 是否检查新文件仅根据文件名还是完整路径(默认值:false)。设置为true时,以下文件将被视为相同的文件,因为它们的文件名“dataset.txt”相同 : “file:///dataset.txt” “s3://a/dataset.txt” “s3n://a/b/dataset.txt” “s3a://a/b/c/dataset.txt” 有关文件格式的特定选项,请参见 DataStreamReader (Scala/Java/Python/R) 中的相关方法。例如,有关“parquet”格式选项,请参见DataStreamReader.parquet() 。此外,还有一些会话配置会影响某些文件格式。有关详细信息,请参阅SQL编程指南。例如,“parquet”参见 Parquet configuration 部分。 |
Yes | Supports glob paths, but does not support multiple comma-separated paths/globs. |
| Socket Source | host: host to connect to, must be specified port: port to connect to, must be specified |
No | |
| Rate Source 速率源 |
rowsPerSecond (e.g. 100, default: 1): How many rows should be generated per second. rampUpTime (e.g. 5s, default: 0s): How long to ramp up before the generating speed becomes rowsPerSecond. Using finer granularities than seconds will be truncated to integer seconds. numPartitions (e.g. 10, default: Spark’s default parallelism): The partition number for the generated rows. The source will try its best to reach rowsPerSecond, but the query may be resource constrained, and numPartitions can be tweaked to help reach the desired speed.rowsPerSecond(例如 100s,默认值:1):每秒应生成多少行。rampUpTime(例如 5s,默认值:0s):在生成速度变为 rowsPerSecond 秒之前,需要多长时间进行加速。使用比秒细的粒度将被截断为整数秒。numPartitions(例如10,默认值:Spark的默认并行度):生成行的分区数量。源将尽力达到rowsPerSecond,但查询可能受到资源限制,可以调整 numPartitions 以帮助达到请求的速度。 |
Yes | |
| Kafka Source | See the Kafka Integration Guide. | Yes | |
| Here are some examples. |
这里是一些例子。
1 | val spark: SparkSession = ... |
These examples generate streaming DataFrames that are untyped, meaning that the schema of the DataFrame is not checked at compile time, only checked at runtime when the query is submitted. Some operations like map, flatMap, etc. need the type to be known at compile time. To do those, you can convert these untyped streaming DataFrames to typed streaming Datasets using the same methods as static DataFrame. See the SQL Programming Guide for more details. Additionally, more details on the supported streaming sources are discussed later in the document.
这些示例生成未类型化的流式 DataFrame ,这意味着在编译时不检查 DataFrame 的模式(schema),只有当提交查询,在运行时检查。一些操作(如 map、flatmap 等)需要在编译时知道类型。为此,您可以使用与静态 DataFrame 相同的方法将这些非类型化的流 DataFrame 转换为类型化的流数据集。有关详细信息,请参阅SQL编程指南。此外,有关支持的流源的更多详细信息将在文档的后面讨论。
Schema inference and partition of streaming DataFrames/Datasets
流式数据帧/DataSet 的模式推断和划分
By default, Structured Streaming from file based sources requires you to specify the schema, rather than rely on Spark to infer it automatically. This restriction ensures a consistent schema will be used for the streaming query, even in the case of failures. For ad-hoc use cases, you can reenable schema inference by setting spark.sql.streaming.schemaInference to true.
默认情况下,来自基于文件的源的结构化流要求您指定模式,而不是依靠Spark自动推断模式。此限制确保流式查询使用一致的模式,即使在失败的情况下也是如此。对于特殊的用例,可以通过将 spark.sql.streaming.schemaInference 设置为true来重新启用模式推断。
Partition discovery does occur when subdirectories that are named /key=value/ are present and listing will automatically recurse into these directories. If these columns appear in the user-provided schema, they will be filled in by Spark based on the path of the file being read. The directories that make up the partitioning scheme must be present when the query starts and must remain static. For example, it is okay to add /data/year=2016/ when /data/year=2015/ was present, but it is invalid to change the partitioning column (i.e. by creating the directory /data/date=2016-04-17/).
如果存在名为 /key=value/ 的子目录,并且列表将自动递归到这些目录中,则会发生分区发现。如果这些列出现在用户提供的模式中,它们将由 Spark 根据正在读取的文件的路径填充。组成分区方案的目录必须在查询开始时存在,并且必须保持静态。例如,可以在 /data/year=2015/ 存在时添加 /data/year=2016/ 但更改分区列无效(即通过创建目录 /data/date=2016-04-17/)。
Operations on streaming DataFrames/Datasets
流式数据帧/数据集上的操作
You can apply all kinds of operations on streaming DataFrames/Datasets – ranging from untyped, SQL-like operations (e.g. select, where, groupBy), to typed RDD-like operations (e.g. map, filter, flatMap). See the SQL programming guide for more details. Let’s take a look at a few example operations that you can use.
您可以对流式 DataFrame/Dataset 应用各种操作—从非类型化、类SQL操作(例如 select、where、groupBy)到类RDD操作(例如 map、filter、flatmap)。有关详细信息,请参阅SQL编程指南。让我们来看几个您可以使用的示例操作。
Basic Operations - Selection, Projection, Aggregation
基本操作(选择、投影、聚合)
Most of the common operations on DataFrame/Dataset are supported for streaming. The few operations that are not supported are discussed later in this section.
DataFrame/Dataset 上的大多数常见操作都支持流式处理。本节稍后将讨论一些不受支持的操作。
1 | case class DeviceData(device: String, deviceType: String, signal: Double, time: DateTime) |
You can also register a streaming DataFrame/Dataset as a temporary view and then apply SQL commands on it.
还可以将流式 DataFrame/Dataset 注册为临时视图,然后对其应用 SQL 命令。
1 | df.createOrReplaceTempView("updates") |
Note, you can identify whether a DataFrame/Dataset has streaming data or not by using df.isStreaming.
注意,可以使用 df.isStreaming 来标识数据帧/数据集是否具有流数据。
1 | df.isStreaming |
Window Operations on Event Time
事件时间的窗口操作
Aggregations over a sliding event-time window are straightforward with Structured Streaming and are very similar to grouped aggregations. In a grouped aggregation, aggregate values (e.g. counts) are maintained for each unique value in the user-specified grouping column. In case of window-based aggregations, aggregate values are maintained for each window the event-time of a row falls into. Let’s understand this with an illustration.
滑动事件时间窗口上的聚合对于结构化流非常简单,并且与分组聚合非常相似。在分组聚合中,为用户指定的分组列中的每个唯一值维护聚合值(例如计数)。对于基于窗口的聚合,将为行的事件时间所在的每个窗口维护聚合值。让我们用一个例子来理解这一点。
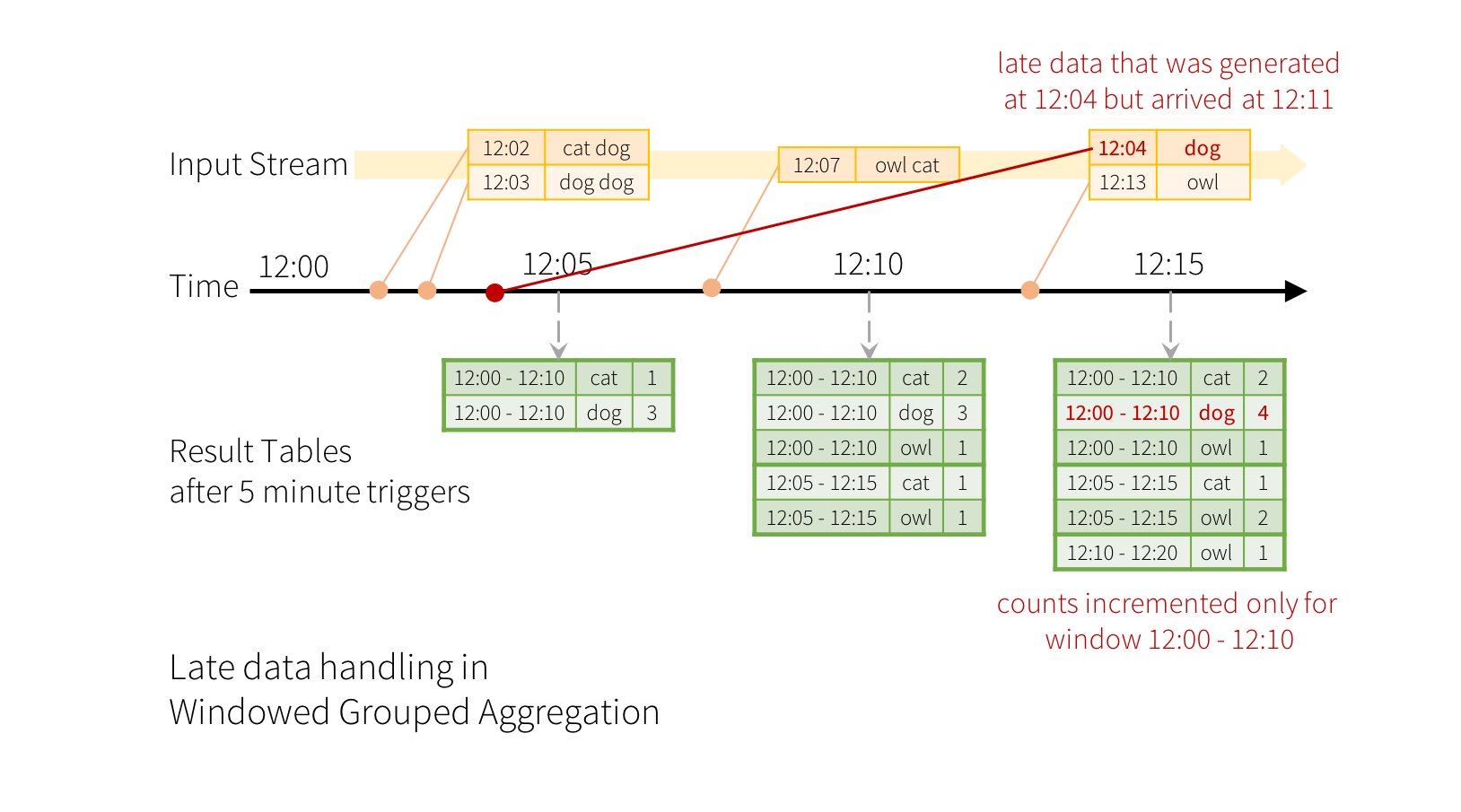
Imagine our quick example is modified and the stream now contains lines along with the time when the line was generated. Instead of running word counts, we want to count words within 10 minute windows, updating every 5 minutes. That is, word counts in words received between 10 minute windows 12:00 - 12:10, 12:05 - 12:15, 12:10 - 12:20, etc. Note that 12:00 - 12:10 means data that arrived after 12:00 but before 12:10. Now, consider a word that was received at 12:07. This word should increment the counts corresponding to two windows 12:00 - 12:10 and 12:05 - 12:15. So the counts will be indexed by both, the grouping key (i.e. the word) and the window (can be calculated from the event-time).
假设我们的快速示例被修改了,流现在包含了行以及生成行的时间。我们不需要运行单词计数,而是希望在10分钟的窗口内对单词进行计数,每5分钟更新一次。也就是说,单词在10分钟窗口12:00-12:10、12:05-12:15、12:10-12:20等之间接收的单词中计数。请注意,12:00-12:10表示12:00之后但12:10之前到达的数据。现在,考虑一下12:07收到的一个词。这个词应该增加对应于两个窗口12:00-12:10和12:05-12:15的计数。因此,计数将由分组键(即字)和窗口(可以从事件时间计算)这两个参数索引。
The result tables would look something like the following.
结果表如下所示。
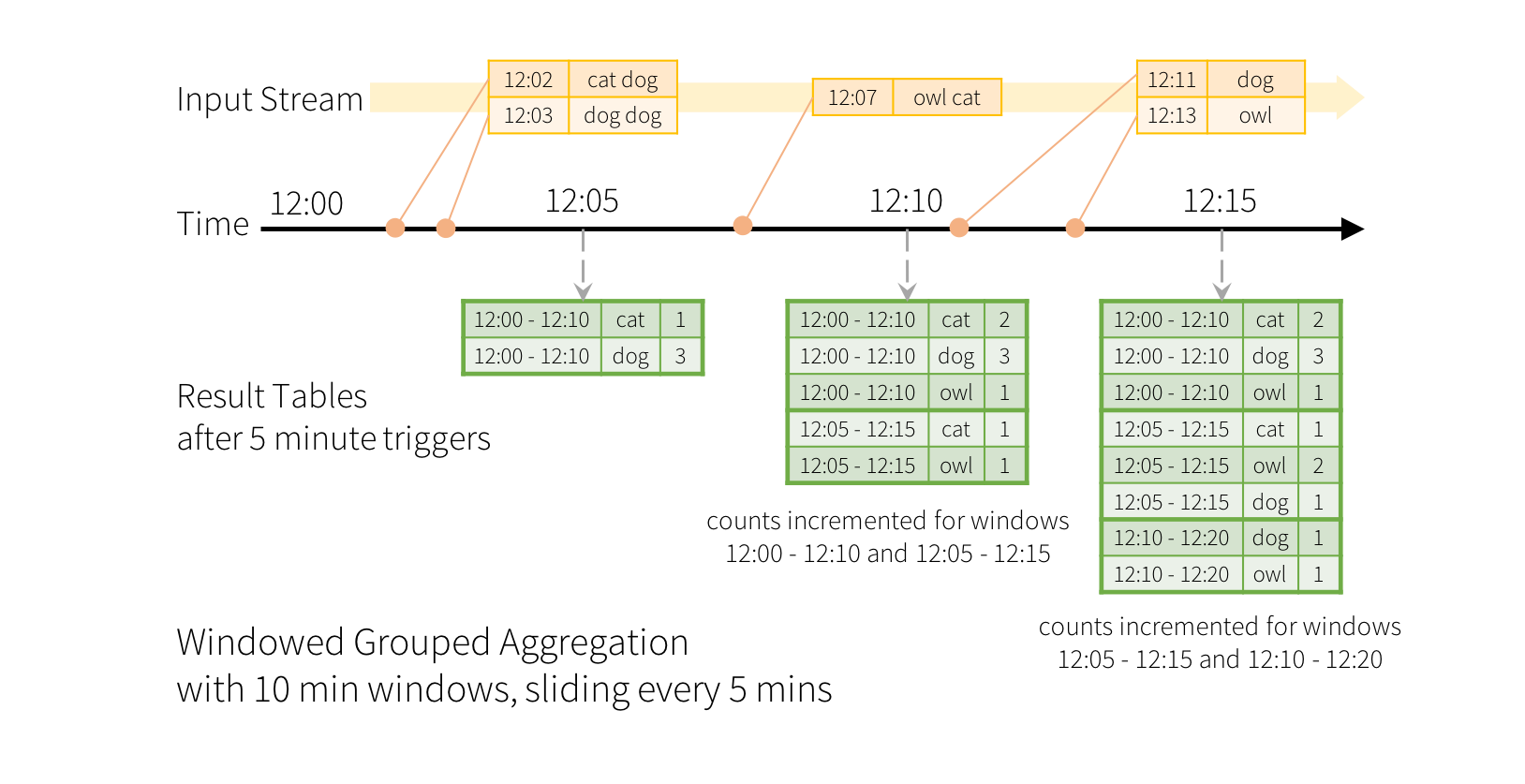
Since this windowing is similar to grouping, in code, you can use groupBy() and window() operations to express windowed aggregations. You can see the full code for the below examples in Scala/Java/Python.
由于此窗口化与分组类似,因此在代码中,可以使用 groupBy() 和 window() 操作来表示窗口化聚合。您可以在 Scala/Java/Python 中看到下面的示例的完整代码。
1 | import spark.implicits._ |
Handling Late Data and Watermarking
处理延迟数据和水印
Now consider what happens if one of the events arrives late to the application. For example, say, a word generated at 12:04 (i.e. event time) could be received by the application at 12:11. The application should use the time 12:04 instead of 12:11 to update the older counts for the window 12:00 - 12:10. This occurs naturally in our window-based grouping – Structured Streaming can maintain the intermediate state for partial aggregates for a long period of time such that late data can update aggregates of old windows correctly, as illustrated below.
现在考虑一下如果其中一个事件延迟到达应用程序会发生什么。例如,在12:04(即事件时间)生成的单词可以在12:11被应用程序接收。应用程序应使用时间12:04而不是12:11更新窗口12:00-12:10的旧计数。这在基于窗口的分组中自然发生——结构化流可以长时间保持部分聚合的中间状态,以便后期数据可以正确更新旧窗口的聚合,如下图所示。
However, to run this query for days, it’s necessary for the system to bound the amount of intermediate in-memory state it accumulates. This means the system needs to know when an old aggregate can be dropped from the in-memory state because the application is not going to receive late data for that aggregate any more. To enable this, in Spark 2.1, we have introduced watermarking, which lets the engine automatically track the current event time in the data and attempt to clean up old state accordingly. You can define the watermark of a query by specifying the event time column and the threshold on how late the data is expected to be in terms of event time. For a specific window ending at time T, the engine will maintain state and allow late data to update the state until (max event time seen by the engine - late threshold > T). In other words, late data within the threshold will be aggregated, but data later than the threshold will start getting dropped (see later in the section for the exact guarantees). Let’s understand this with an example. We can easily define watermarking on the previous example using withWatermark() as shown below.
但是,要运行这个查询几天,系统必须绑定它在内存状态中累积的一定数量的中间状态。这意味着系统需要知道何时可以从内存状态中除去旧聚合,因为应用程序将不再接收该聚合的延迟数据。为了实现这一点,在Spark2.1中,我们引入了水印技术,它允许引擎自动跟踪数据中的当前事件时间,并尝试相应地清除旧状态。您可以通过指定事件时间列和阈值来定义查询的水印,该阈值说明数据在事件时间方面的预计延迟时间。对于在时间 t 结束的特定窗口,引擎将保持状态并允许延迟数据更新状态,直到(引擎看到的最大事件时间-延迟阈值>t)。换句话说,阈值内的延迟数据将被聚合,但超过阈值的数据将开始去除(有关精确的保证,请参阅本节后面的部分)。让我们用一个例子来理解这一点。我们可以很容易地使用 withwatermark() 在前面的示例中定义水印,如下所示。
1 | import spark.implicits._ |
In this example, we are defining the watermark of the query on the value of the column “timestamp”, and also defining “10 minutes” as the threshold of how late is the data allowed to be. If this query is run in Update output mode (discussed later in Output Modes section), the engine will keep updating counts of a window in the Result Table until the window is older than the watermark, which lags behind the current event time in column “timestamp” by 10 minutes. Here is an illustration.
在本例中,我们在”timestamp“ 列的值上定义了查询的水印 ,还定义了“10分钟”作为允许数据延迟的阈值。如果在更新输出模式下运行此查询(稍后在输出模式部分中讨论),则引擎将继续更新结果表中窗口的计数,直到窗口比水印旧,而水印比“timestamp”列中的当前事件时间落后10分钟。这是一个例子。
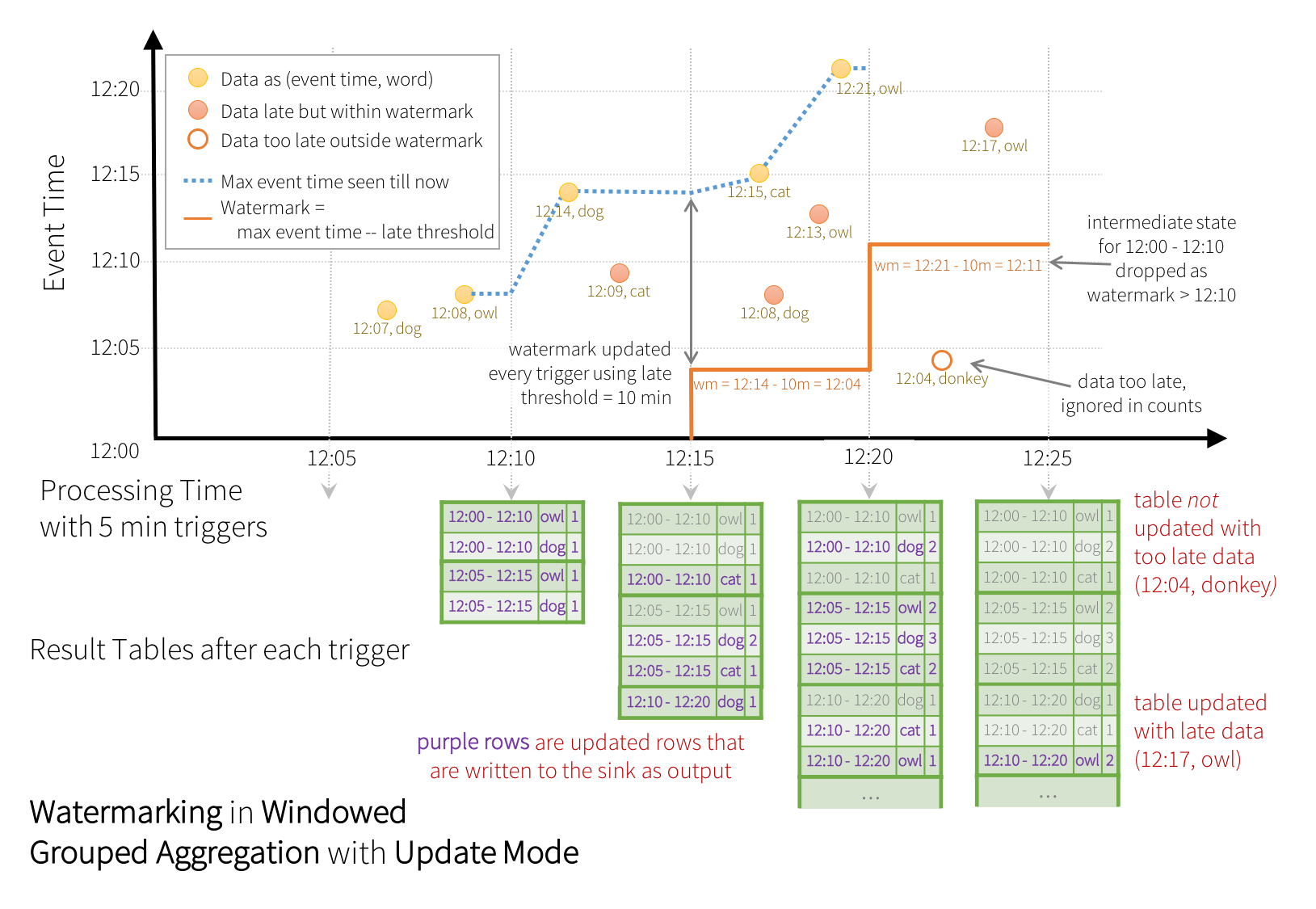
As shown in the illustration, the maximum event time tracked by the engine is the blue dashed line, and the watermark set as (max event time - '10 mins') at the beginning of every trigger is the red line. For example, when the engine observes the data (12:14, dog), it sets the watermark for the next trigger as 12:04. This watermark lets the engine maintain intermediate state for additional 10 minutes to allow late data to be counted. For example, the data (12:09, cat) is out of order and late, and it falls in windows 12:00 - 12:10 and 12:05 - 12:15. Since, it is still ahead of the watermark 12:04 in the trigger, the engine still maintains the intermediate counts as state and correctly updates the counts of the related windows. However, when the watermark is updated to 12:11, the intermediate state for window (12:00 - 12:10) is cleared, and all subsequent data (e.g. (12:04, donkey)) is considered “too late” and therefore ignored. Note that after every trigger, the updated counts (i.e. purple rows) are written to sink as the trigger output, as dictated by the Update mode.
如图所示,引擎跟踪的最大事件时间是蓝色虚线,每个触发器开始时设置为(最大事件时间-“10分钟”)的水印是红线。例如,当引擎观察数据(12:14,dog)时,它将下一个触发器的水印设置为12:04。这个水印允许引擎在额外的10分钟内保持中间状态,以便计算延迟的数据。例如,数据(12:09,cat)出现故障和延迟,并落在Windows 12:00-12:10和12:05-12:15中。由于它仍在触发器中的水印12:04之前,因此引擎仍将中间计数保持为状态,并正确更新相关窗口的计数。但是,当水印更新到12:11时,窗口的中间状态(12:00-12:10)被清除,所有后续数据(例如(12:04,donkey))被视为“太晚”,因此被忽略。请注意,在每个触发器之后,更新的计数(即紫色行)都会写入sink作为触发器输出,这由更新模式决定。
Some sinks (e.g. files) may not supported fine-grained updates that Update Mode requires. To work with them, we have also support Append Mode, where only the final counts are written to sink. This is illustrated below.
某些接收器(如文件)可能不支持更新模式所需的细粒度更新。为了使用它们,我们还支持附加模式,其中只有最终计数被写入sink。如下所示。
Note that using withWatermark on a non-streaming Dataset is no-op. As the watermark should not affect any batch query in any way, we will ignore it directly.
请注意,对非流式 Dataset 使用 withWatermark 是不起作用的。由于水印不应以任何方式影响任何批查询,因此我们将直接忽略它。
Similar to the Update Mode earlier, the engine maintains intermediate counts for each window. However, the partial counts are not updated to the Result Table and not written to sink. The engine waits for “10 mins” for late date to be counted, then drops intermediate state of a window < watermark, and appends the final counts to the Result Table/sink. For example, the final counts of window 12:00 - 12:10 is appended to the Result Table only after the watermark is updated to 12:11.
与之前的更新模式类似,引擎为每个窗口保持中间计数。但是,部分计数不会更新到结果表,也不会写入接收器。引擎等待“10分钟”计算延迟时间,然后将窗口<水印的中间状态剔除,并将最终计数附加到结果表/接收器。例如,只有在水印更新为12:11之后,才会将窗口12:00-12:10的最终计数追加到结果表中。
Conditions for watermarking to clean aggregation state
水印清除聚合状态的条件
It is important to note that the following conditions must be satisfied for the watermarking to clean the state in aggregation queries (as of Spark 2.1.1, subject to change in the future).
需要注意的是,水印必须满足以下条件才能清除聚合查询中的状态(从spark 2.1.1开始,以后可能会更改)。
Output mode must be Append or Update. Complete mode requires all aggregate data to be preserved, and hence cannot use watermarking to drop intermediate state. See the Output Modes section for detailed explanation of the semantics of each output mode.
输出模式必须是追加或更新。完整模式要求保留所有聚合数据,因此不能使用水印删除中间状态。有关每个输出模式语义的详细说明,请参阅输出模式部分。
The aggregation must have either the event-time column, or a
windowon the event-time column.聚合必须具有事件时间列或事件时间列上的窗口。
withWatermarkmust be called on the same column as the timestamp column used in the aggregate. For example,df.withWatermark("time", "1 min").groupBy("time2").count()is invalid in Append output mode, as watermark is defined on a different column from the aggregation column.必须在与聚合中使用的时间戳列相同的列上调用
withWatermark。例如,df.withWatermark("time", "1 min").groupBy("time2").count()在追加输出模式下无效,因为水印是在聚合列的不同列上定义的。withWatermarkmust be called before the aggregation for the watermark details to be used. For example,df.groupBy("time").count().withWatermark("time", "1 min")is invalid in Append output mode.必须在聚合之前调用
withWatermark才能使用水印详细信息。例如,df.groupBy("time").count().withWatermark("time", "1 min")在追加输出模式下无效。
Semantic Guarantees of Aggregation with Watermarking
具有水印的聚合的语义保证
A watermark delay (set with
withWatermark) of “2 hours” guarantees that the engine will never drop any data that is less than 2 hours delayed. In other words, any data less than 2 hours behind (in terms of event-time) the latest data processed till then is guaranteed to be aggregated.水印延迟(用水印设置)为“2小时”,保证引擎不会丢弃任何延迟时间小于2小时的数据。换言之,任何比最新处理的数据晚2小时(就事件时间而言)以内的数据都保证被聚合。
However, the guarantee is strict only in one direction. Data delayed by more than 2 hours is not guaranteed to be dropped; it may or may not get aggregated. More delayed is the data, less likely is the engine going to process it.
但是,担保只在一个方向上是严格的。延迟超过2小时的数据不一定会被删除;它可能会被聚合,也可能不会被聚合。数据越晚,引擎处理数据的可能性就越小。
Join Operations
连接操作
Structured Streaming supports joining a streaming Dataset/DataFrame with a static Dataset/DataFrame as well as another streaming Dataset/DataFrame. The result of the streaming join is generated incrementally, similar to the results of streaming aggregations in the previous section. In this section we will explore what type of joins (i.e. inner, outer, etc.) are supported in the above cases. Note that in all the supported join types, the result of the join with a streaming Dataset/DataFrame will be the exactly the same as if it was with a static Dataset/DataFrame containing the same data in the stream.
结构化流支持将流 Dataset/DataFrame 与静态 Dataset/DataFrame 以及另一个 Dataset/DataFrame 连接起来。流连接的结果是增量生成的,类似于上一节中的流聚合结果。在本节中,我们将探讨在上述情况下支持的连接类型(即内部、外部等)。请注意,在所有支持的连接类型中,使用流 Dataset/DataFrame 进行连接的结果将与使用流中包含相同数据的静态 Dataset/DataFrame 时的结果完全相同。
Stream-static Joins
流与静态数据的连接
Since the introduction in Spark 2.0, Structured Streaming has supported joins (inner join and some type of outer joins) between a streaming and a static DataFrame/Dataset. Here is a simple example.
自从 Spark2.0 引入以来,结构化流支持流和静态 DataFrame/Dataset 之间的连接(内部连接和某些类型的外部连接)。下面是一个简单的例子。
1 | val staticDf = spark.read. ... |
Note that stream-static joins are not stateful, so no state management is necessary. However, a few types of stream-static outer joins are not yet supported. These are listed at the end of this Join section.
注意,流静态连接不是有状态的,因此不需要状态管理。但是,还不支持几种类型的流静态外部联接。这些列在这个连接章节的末尾。
Stream-stream Joins
流与流数据的连接
In Spark 2.3, we have added support for stream-stream joins, that is, you can join two streaming Datasets/DataFrames. The challenge of generating join results between two data streams is that, at any point of time, the view of the dataset is incomplete for both sides of the join making it much harder to find matches between inputs. Any row received from one input stream can match with any future, yet-to-be-received row from the other input stream. Hence, for both the input streams, we buffer past input as streaming state, so that we can match every future input with past input and accordingly generate joined results. Furthermore, similar to streaming aggregations, we automatically handle late, out-of-order data and can limit the state using watermarks. Let’s discuss the different types of supported stream-stream joins and how to use them.
在 Spark 2.3 中,我们增加了对流流连接的支持,也就是说,您可以连接两个流 Datasets/DataFrames。在两个数据流之间生成连接结果的挑战在于,在任何时候,数据集的视图对于连接的两边都是不完整的,因此很难找到输入之间的匹配。从一个输入流接收到的任何行都可以与将来的任何行匹配,但仍将从另一个输入流接收到该行。因此,对于这两个输入流,我们将过去的输入缓冲为流状态,这样我们可以将未来的每个输入与过去的输入匹配,并相应地生成联接的结果。此外,与流聚合类似,我们自动处理延迟的无序数据,并可以使用水印限制状态。让我们讨论支持的流连接的不同类型以及如何使用它们。
Inner Joins with optional Watermarking
带有可选水印的内部联接
Inner joins on any kind of columns along with any kind of join conditions are supported. However, as the stream runs, the size of streaming state will keep growing indefinitely as all past input must be saved as any new input can match with any input from the past. To avoid unbounded state, you have to define additional join conditions such that indefinitely old inputs cannot match with future inputs and therefore can be cleared from the state. In other words, you will have to do the following additional steps in the join.
支持任何类型的列上的内部联接以及任何类型的连接条件。但是,当流运行时,流状态的大小将无限期地增长,因为必须保存所有过去的输入,因为任何新输入都可以与过去的任何输入匹配。为了避免无边界状态,您必须定义额外的连接条件,以便使无限期旧的输入不能与将来的输入匹配,因此可以从状态中清除。换句话说,您必须在连接中执行以下附加步骤。
Define watermark delays on both inputs such that the engine knows how delayed the input can be (similar to streaming aggregations)
在两个输入上定义水印延迟,以便引擎知道输入的延迟程度(类似于流聚合)。
Define a constraint on event-time across the two inputs such that the engine can figure out when old rows of one input is not going to be required (i.e. will not satisfy the time constraint) for matches with the other input. This constraint can be defined in one of the two ways.
在两个输入之间定义一个事件时间约束,这样引擎就可以计算出一个输入的旧行(表格的行)何时不需要(即不满足时间约束)与另一个输入匹配。这个约束可以用两种方法之一定义。
Time range join conditions (e.g.
...JOIN ON leftTime BETWEEN rightTime AND rightTime + INTERVAL 1 HOUR),时间范围连接条件(例如,
...JOIN ON leftTime BETWEEN rightTime AND rightTime + INTERVAL 1 HOUR)Join on event-time windows (e.g.
...JOIN ON leftTimeWindow = rightTimeWindow).在事件时间窗口上连接(例如,
...JOIN ON leftTimeWindow = rightTimeWindow)。
Let’s understand this with an example.
让我们用一个例子来理解这一点。
Let’s say we want to join a stream of advertisement impressions (when an ad was shown) with another stream of user clicks on advertisements to correlate when impressions led to monetizable clicks. To allow the state cleanup in this stream-stream join, you will have to specify the watermarking delays and the time constraints as follows.
假设我们想将一个广告印象流(显示广告时)与另一个用户点击广告流连接起来,以便在广告印象导致可盈利点击时进行关联。要允许此流连接中的状态清理,您必须指定水印延迟和时间约束,如下所示。
Watermark delays: Say, the impressions and the corresponding clicks can be late/out-of-order in event-time by at most 2 and 3 hours, respectively.
水印延迟:例如,事件时间中的广告印象和相应的点击可能延迟/无序,分别最多2小时和3小时。
Event-time range condition: Say, a click can occur within a time range of 0 seconds to 1 hour after the corresponding impression.
事件时间范围条件:例如,在相应的广告印象后0秒到1小时的时间范围内可能会发生一次单击。
The code would look like this.
代码应该是这样的。
1 | import org.apache.spark.sql.functions.expr |
Semantic Guarantees of Stream-stream Inner Joins with Watermarking
带水印的流之间的内部连接的语义保证
This is similar to the guarantees provided by watermarking on aggregations. A watermark delay of “2 hours” guarantees that the engine will never drop any data that is less than 2 hours delayed. But data delayed by more than 2 hours may or may not get processed.
这类似于在聚合上添加水印提供的保证。水印延迟“2小时”保证引擎不会丢弃任何延迟时间小于2小时的数据。但延迟超过2小时的数据可能会被处理,也可能不会被处理。
Outer Joins with Watermarking
带水印的外部连接
While the watermark + event-time constraints is optional for inner joins, for left and right outer joins they must be specified. This is because for generating the NULL results in outer join, the engine must know when an input row is not going to match with anything in future. Hence, the watermark + event-time constraints must be specified for generating correct results. Therefore, a query with outer-join will look quite like the ad-monetization example earlier, except that there will be an additional parameter specifying it to be an outer-join.
对于内部联接,水印+事件时间约束是可选的,而对于左侧和右侧外部连接,则必须指定它们。这是因为为了在外部连接中生成 NULL 结果,引擎必须知道输入行在将来什么时候不会与任何内容匹配。因此,必须指定水印+事件时间约束以生成正确的结果。因此,具有外部连接的查询看起来很像前面的广告货币化示例,只是有一个额外的参数将其指定为外部连接。
1 | impressionsWithWatermark.join( |
Semantic Guarantees of Stream-stream Outer Joins with Watermarking
带水印的流外部连接的语义保证
Outer joins have the same guarantees as inner joins regarding watermark delays and whether data will be dropped or not.
外部联接与内部联接在水印延迟以及是否删除数据方面具有相同的保证。
Caveats
注意事项
There are a few important characteristics to note regarding how the outer results are generated.
关于外部结果是如何产生的,需要注意一些重要特征。
The outer NULL results will be generated with a delay that depends on the specified watermark delay and the time range condition. This is because the engine has to wait for that long to ensure there were no matches and there will be no more matches in future.
外部 NULL 结果将根据指定的水印延迟和时间范围条件生成延迟。这是因为引擎必须等待那么长的时间,以确保没有匹配,将来也不会有更多的匹配。
In the current implementation in the micro-batch engine, watermarks are advanced at the end of a micro-batch, and the next micro-batch uses the updated watermark to clean up state and output outer results. Since we trigger a micro-batch only when there is new data to be processed, the generation of the outer result may get delayed if there no new data being received in the stream. In short, if any of the two input streams being joined does not receive data for a while, the outer (both cases, left or right) output may get delayed.
在微批量引擎的当前实现中,水印是在微批量的末尾的后期,下一个微批量使用更新后的水印来清除状态并输出外部结果。由于我们只在有新数据要处理时触发一个微批处理,因此如果流中没有接收到新数据,则外部结果的生成可能会延迟。简而言之,如果被连接的两个输入流中的任何一个在一段时间内没有接收数据,则外部(两种情况下,左侧或右侧)输出可能会延迟。
Support matrix for joins in streaming queries
流式查询中连接的支持矩阵
| Left Input | Right Input | Join Type | |
|---|---|---|---|
| Static | Static | All types | Supported, since its not on streaming data even though it can be present in a streaming query支持,可以在两侧指定水印+状态清理的时间限制 |
| Stream | Static | Inner | Supported, not stateful |
| Left Outer | Supported, not stateful | ||
| Right Outer | Not supported | ||
| Full Outer | Not supported | ||
| Static | Stream | Inner | Supported, not stateful |
| Left Outer | Not supported | ||
| Right Outer | Supported, not stateful | ||
| Full Outer | Not supported | ||
| Stream | Stream | Inner | Supported, optionally specify watermark on both sides + time constraints for state cleanup 支持,可以在两侧指定水印状态清理的时间限制 |
| Left Outer | Conditionally supported, must specify watermark on right + time constraints for correct results, optionally specify watermark on left for all state cleanup 条件支持,必须在正确的时间限制上指定水印才能获得正确的结果,也可以为所有状态清理指定左侧水印 | ||
| Right Outer | Conditionally supported, must specify watermark on left + time constraints for correct results, optionally specify watermark on right for all state cleanup 条件支持,必须在左侧指定水印时间约束才能获得正确的结果,也可以在右侧指定水印以进行所有状态清理。 | ||
| Full Outer | Not supported |
Additional details on supported joins:
关于所支持的连接的其他细节:
Joins can be cascaded, that is, you can do
df1.join(df2, ...).join(df3, ...).join(df4, ....).连接可以级联,也就是说,您可以执行
df1.join(df2, ...).join(df3, ...).join(df4, ....)As of Spark 2.3, you can use joins only when the query is in Append output mode. Other output modes are not yet supported.
从spark 2.3开始,只有当查询处于追加输出模式时,才能使用连接。还不支持其他输出模式。
As of Spark 2.3, you cannot use other non-map-like operations before joins. Here are a few examples of what cannot be used.
从Spark 2.3开始,连接之前不能使用其他非映射类操作。以下是一些无法使用的示例。
Cannot use streaming aggregations before joins.
在连接之前不能使用流聚合
Cannot use
mapGroupsWithStateandflatMapGroupsWithStatein Update mode before joins.在连接之前,不能在更新模式中使用
mapGroupsWithState和flatMapGroupsWithState。
Streaming Deduplication
流的去重
You can deduplicate records in data streams using a unique identifier in the events. This is exactly same as deduplication on static using a unique identifier column. The query will store the necessary amount of data from previous records such that it can filter duplicate records. Similar to aggregations, you can use deduplication with or without watermarking.
可以使用事件中的唯一标识符来消除数据流中的重复记录。这与使用唯一标识符列的静态重复数据消除完全相同。查询将存储来自以前记录中所需的数据,以便可以过滤重复记录。与聚合类似,您可以使用带或不带水印的重复数据消除。
With watermark - If there is a upper bound on how late a duplicate record may arrive, then you can define a watermark on a event time column and deduplicate using both the guid and the event time columns. The query will use the watermark to remove old state data from past records that are not expected to get any duplicates any more. This bounds the amount of the state the query has to maintain.
使用水印——如果重复记录到达的时间有上限,则可以在事件时间列上定义水印,并使用 guid 和事件时间列进行重复数据消除。查询将使用水印从过去的记录中删除旧的状态数据,这些记录不希望再得到任何重复数据。这限制了查询必须维护的状态量。
Without watermark - Since there are no bounds on when a duplicate record may arrive, the query stores the data from all the past records as state.
没有水印——由于重复记录可能到达的时间没有界限,查询将所有过去记录的数据存储为状态。
1 | val streamingDf = spark.readStream. ... // columns: guid, eventTime, ... |
Policy for handling multiple watermarks
处理多个水印的策略
A streaming query can have multiple input streams that are unioned or joined together. Each of the input streams can have a different threshold of late data that needs to be tolerated for stateful operations. You specify these thresholds using withWatermarks("eventTime", delay) on each of the input streams. For example, consider a query with stream-stream joins between inputStream1 and inputStream2.
流查询可以有多个联合或连接在一起的输入流。每个输入流可以有一个不同的延迟数据阈值,对于有状态的操作,这些阈值需要被容忍。在每个输入流上使用 withWatermarks("eventTime", delay) 指定这些阈值。例如,考虑使用 inputStream1 和 inputStream2 之间的流连接进行查询。
1 | inputStream1.withWatermark(“eventTime1”, “1 hour”) .join( inputStream2.withWatermark(“eventTime2”, “2 hours”), joinCondition) |
While executing the query, Structured Streaming individually tracks the maximum event time seen in each input stream, calculates watermarks based on the corresponding delay, and chooses a single global watermark with them to be used for stateful operations. By default, the minimum is chosen as the global watermark because it ensures that no data is accidentally dropped as too late if one of the streams falls behind the others (for example, one of the streams stop receiving data due to upstream failures). In other words, the global watermark will safely move at the pace of the slowest stream and the query output will be delayed accordingly.
在执行查询时,结构化流单独跟踪每个输入流中看到的最大事件时间,根据相应的延迟计算水印,并选择一个带有它们的全局水印用于状态操作。默认情况下,选择最小值作为全局水印,因为这样可以确保如果其中一个流落后于另一个流(例如,其中一个流由于上游故障而停止接收数据),则不会意外地将任何数据拖得太晚。换句话说,全局水印将以最慢流的速度安全移动,查询输出将相应延迟。
However, in some cases, you may want to get faster results even if it means dropping data from the slowest stream. Since Spark 2.4, you can set the multiple watermark policy to choose the maximum value as the global watermark by setting the SQL configuration spark.sql.streaming.multipleWatermarkPolicy to max (default is min). This lets the global watermark move at the pace of the fastest stream. However, as a side effect, data from the slower streams will be aggressively dropped. Hence, use this configuration judiciously.
但是,在某些情况下,您可能希望获得更快的结果,即使这意味着从最慢的流中删除数据。由于Spark 2.4,可以通过将SQL配置 spark.sql.streaming.multipleWatermarkPolicy 设置为 max(默认值为 min),将多水印策略设置为选择最大值作为全局水印。这使得全局水印以最快的流速度移动。但是,作为一个副作用,来自较慢流的数据将被大量丢弃。因此,审慎明智地使用这个配置。
Arbitrary Stateful Operations
任意状态操作
Many usecases require more advanced stateful operations than aggregations. For example, in many usecases, you have to track sessions from data streams of events. For doing such sessionization, you will have to save arbitrary types of data as state, and perform arbitrary operations on the state using the data stream events in every trigger. Since Spark 2.2, this can be done using the operation mapGroupsWithState and the more powerful operation flatMapGroupsWithState. Both operations allow you to apply user-defined code on grouped Datasets to update user-defined state. For more concrete details, take a look at the API documentation (Scala/Java) and the examples (Scala/Java).
许多用例需要比聚合更高级的有状态操作。例如,在许多用例中,您必须从事件的数据流中跟踪会话。为了进行这种会话化,必须将任意类型的数据保存为状态,并使用每个触发器中的数据流事件对状态执行任意操作。由于spark 2.2,可以使用操作 mapGroupsWithState 和更强大的操作 flatMapGroupsWithState 来完成此操作。这两个操作都允许您对分组数据集应用用户定义的代码以更新用户定义的状态。有关更具体的细节,请看API文档(Scala/Java)和示例(Scala/Java)。
Unsupported Operations
不支持的操作
There are a few DataFrame/Dataset operations that are not supported with streaming DataFrames/Datasets. Some of them are as follows.
流式 DataFrame/Dataset 不支持一些 DataFrame/Dataset 操作。其中一些如下。
Multiple streaming aggregations (i.e. a chain of aggregations on a streaming DF) are not yet supported on streaming Datasets.
流 Datasets 尚不支持多个流聚合(即流数据集中的聚合链)。
Limit and take first N rows are not supported on streaming Datasets.
流 Datasets 不支持限制行和取前n行。
Distinct operations on streaming Datasets are not supported.
不支持对流数据集执行
Distinct的操作。Sorting operations are supported on streaming Datasets only after an aggregation and in Complete Output Mode.
只有在聚合之后并且处于完全输出模式时,流 Datasets 才支持排序操作。
Few types of outer joins on streaming Datasets are not supported. See the support matrix in the Join Operations section for more details.
不支持流 Datasets 上的几种类型的外部连接。有关详细信息,请参阅“连接操作”部分中的支持矩阵。
In addition, there are some Dataset methods that will not work on streaming Datasets. They are actions that will immediately run queries and return results, which does not make sense on a streaming Dataset. Rather, those functionalities can be done by explicitly starting a streaming query (see the next section regarding that).
此外,还有一些 Dataset 方法不适用于流 Dataset。它们是将立即运行查询并返回结果的操作,这对流 Dataset 没有意义。相反,这些功能可以通过显式启动流式查询来完成(请参见下一节相关内容)
count()- Cannot return a single count from a streaming Dataset. Instead, useds.groupBy().count()which returns a streaming Dataset containing a running count.count()—— 无法从流数据集中返回单个计数。相反,使用ds.groupBy().count()。foreach()- Instead useds.writeStream.foreach(...)(see next section).foreach()——而是使用ds.writeStream.foreach(...)(看下一节)show()- Instead use the console sink (see next section).show()——而是使用控制台接收器(看下一节)
If you try any of these operations, you will see an AnalysisException like “operation XYZ is not supported with streaming DataFrames/Datasets”. While some of them may be supported in future releases of Spark, there are others which are fundamentally hard to implement on streaming data efficiently. For example, sorting on the input stream is not supported, as it requires keeping track of all the data received in the stream. This is therefore fundamentally hard to execute efficiently.
如果您尝试这些操作中的任何一个,您将看到类似“流式DataFrame/Dataset不支持操作xyz“的AnalysisException。虽然其中一些可能在未来的Spark版本中得到支持,但还有一些基本上难以有效地在流数据上实现。例如,不支持对输入流进行排序,因为它需要跟踪流中接收的所有数据。因此,从根本上说,这很难有效地执行。
Starting Streaming Queries
开始流查询
Once you have defined the final result DataFrame/Dataset, all that is left is for you to start the streaming computation. To do that, you have to use the DataStreamWriter (Scala/Java/Python docs) returned through Dataset.writeStream(). You will have to specify one or more of the following in this interface.
一旦定义了最终结果 DataFrame/Dataset,剩下的就是开始流计算。要做到这一点,您必须使用 Dataset.writeStream() 返回的 DataStreamWriter (Scala/Java/Python 文档)。您必须在此接口中指定以下一个或多个选项。
Details of the output sink: Data format, location, etc.
输出接收器的详细信息:数据格式、位置等。
Output mode: Specify what gets written to the output sink.
输出模式:指定写入输出接收器的内容。
Query name: Optionally, specify a unique name of the query for identification.
查询名称:可选,指定查询的唯一名称以进行标识。
Trigger interval: Optionally, specify the trigger interval. If it is not specified, the system will check for availability of new data as soon as the previous processing has completed. If a trigger time is missed because the previous processing has not completed, then the system will trigger processing immediately.
触发间隔:可选,指定触发间隔。如果未指定,系统将在上一次处理完成后立即检查新数据的可用性。如果由于前一个处理未完成而错过触发时间,则系统将立即触发处理。
Checkpoint location: For some output sinks where the end-to-end fault-tolerance can be guaranteed, specify the location where the system will write all the checkpoint information. This should be a directory in an HDFS-compatible fault-tolerant file system. The semantics of checkpointing is discussed in more detail in the next section.
检查点位置:对于一些可以保证端到端容错的输出接收器,指定系统写入所有检查点信息的位置。这应该是HDFS兼容的容错文件系统中的一个目录。下一节将更详细地讨论检查点的语义。
Output Modes
输出模式
There are a few types of output modes.
有几种输出模式1
Append mode (default) - This is the default mode, where only the new rows added to the Result Table since the last trigger will be outputted to the sink. This is supported for only those queries where rows added to the Result Table is never going to change. Hence, this mode guarantees that each row will be output only once (assuming fault-tolerant sink). For example, queries with only
select,where,map,flatMap,filter,join, etc. will support Append mode.追加模式(默认)——这是默认模式,其中只有自上一个触发器以来添加到结果表的新行才会输出到接收器。只有添加到结果表的行永远不会更改的查询才支持此功能。因此,此模式保证每行只输出一次(假设容错接收器)。例如,只有
select,where,map,flatMap,filter,join等的查询将支持追加模式。Complete mode - The whole Result Table will be outputted to the sink after every trigger. This is supported for aggregation queries.
完成模式——每次触发后,整个结果表都将输出到接收器。聚合查询支持此功能。
Update mode - (Available since Spark 2.1.1) Only the rows in the Result Table that were updated since the last trigger will be outputted to the sink. More information to be added in future releases.
更新模式——(从Spark 2.1.1开始可用)只有结果表中自上次触发器以来更新的行将输出到接收器。更多信息将添加到将来的版本中。
Different types of streaming queries support different output modes. Here is the compatibility matrix.
不同类型的流式查询支持不同的输出模式。这是兼容性矩阵。
| Query Type | Supported Output Modes | Notes | |
|---|---|---|---|
| Queries with aggregation | Aggregation on event-time with watermark | Append, Update, Complete |
Append mode uses watermark to drop old aggregation state. But the output of a
windowed aggregation is delayed the late threshold specified in withWatermark() as by
the modes semantics, rows can be added to the Result Table only once after they are
finalized (i.e. after watermark is crossed). See the
Late Data section for more details.
追加模式使用水印删除旧的聚合状态。但是,窗口聚合的输出延迟了 withWatermark()中指定的最晚阈值,因为模式语义,行在完成后(即水印交叉后)只能添加到结果表中一次。有关详细信息,请参阅延迟数据部分。
Update mode uses watermark to drop old aggregation state. 更新模式使用水印删除旧的聚合状态。 Complete mode does not drop old aggregation state since by definition this mode preserves all data in the Result Table. 完整模式不会删除旧的聚合状态,因为根据定义,此模式保留结果表中的所有数据。 |
| Other aggregations | Complete, Update |
Since no watermark is defined (only defined in other category),
old aggregation state is not dropped.
由于未定义水印(仅在其他类别中定义),因此不会删除旧的聚合状态。 Append mode is not supported as aggregates can update thus violating the semantics of this mode. 不支持追加模式,因为聚合可能更新,从而违反了此模式的语义。 |
|
Queries with mapGroupsWithState |
Update | ||
Queries with flatMapGroupsWithState |
Append operation mode | Append |
Aggregations are allowed after flatMapGroupsWithState.
|
| Update operation mode | Update |
Aggregations not allowed after flatMapGroupsWithState.
|
|
Queries with joins |
Append |
Update and Complete mode not supported yet. See the
support matrix in the Join Operations section
for more details on what types of joins are supported.
尚不支持更新和完成模式。有关支持哪些类型的连接的详细信息,请参阅连接操作部分中的支持矩阵。 |
|
| Other queries | Append, Update |
Complete mode not supported as it is infeasible to keep all unaggregated data in the Result Table.
不支持完整模式,因为无法将所有未聚合的数据保留在结果表中。 |
|
Output Sinks
输出接收器
There are a few types of built-in output sinks.
这里有几种的内建的输出接收器
File sink - Stores the output to a directory.
文件接收器——存储输出到文件夹
1
2
3
4writeStream
.format("parquet") // can be "orc", "json", "csv", etc.
.option("path", "path/to/destination/dir")
.start()Kafka sink - Stores the output to one or more topics in Kafka.
Kafka接收器——存储输出到 Kafka 的一个或者更多主题
1
2
3
4
5writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "updates")
.start()Foreach sink - Runs arbitrary computation on the records in the output. See later in the section for more details.
Foreach 接收器——对输出中的记录执行任意计算。有关详细信息,请参阅本节后面的内容。
1
2
3writeStream
.foreach(...)
.start()Console sink (for debugging) - Prints the output to the console/stdout every time there is a trigger. Both, Append and Complete output modes, are supported. This should be used for debugging purposes on low data volumes as the entire output is collected and stored in the driver’s memory after every trigger.
控制台接收器(用于调试)——每次有触发器时都将输出打印到控制台/标准输出。支持附加和完整输出模式。这应该用于在低数据量上进行调试,因为在每次触发之后,整个输出都被收集并存储在驱动程序的内存中。
1
2
3writeStream
.format("console")
.start()Memory sink (for debugging) - The output is stored in memory as an in-memory table. Both, Append and Complete output modes, are supported. This should be used for debugging purposes on low data volumes as the entire output is collected and stored in the driver’s memory. Hence, use it with caution.
内存接收器(用于调试)——输出作为内存表存储在内存中。支持附加和完整输出模式。当整个输出被收集并存储在驱动程序内存中时,这应该用于在低数据量上进行调试。因此,谨慎使用。
1
2
3
4writeStream
.format("memory")
.queryName("tableName")
.start()Some sinks are not fault-tolerant because they do not guarantee persistence of the output and are meant for debugging purposes only. See the earlier section on fault-tolerance semantics. Here are the details of all the sinks in Spark.
有些接收器不能容错,因为它们不能保证输出的持久性,并且仅用于调试目的。请参见前面关于容错语义的部分。以下是 Spark 中所有水槽的细节。
| Sink | Supported Output Modes | Options | Fault-tolerant | Notes |
|---|---|---|---|---|
| File Sink | Append |
path: path to the output directory, must be specified.
For file-format-specific options, see the related methods in DataFrameWriter (Scala/Java/Python/R). E.g. for "parquet" format options see DataFrameWriter.parquet()
|
Yes (exactly-once) | Supports writes to partitioned tables. Partitioning by time may be useful. |
| Kafka Sink | Append, Update, Complete | See the Kafka Integration Guide | Yes (at-least-once) | More details in the Kafka Integration Guide |
| Foreach Sink | Append, Update, Complete | None | Depends on ForeachWriter implementation | More details in the next section |
| ForeachBatch Sink | Append, Update, Complete | None | Depends on the implementation | More details in the next section |
| Console Sink | Append, Update, Complete |
numRows: Number of rows to print every trigger (default: 20)
truncate: Whether to truncate the output if too long (default: true)
|
No | |
| Memory Sink | Append, Complete | None | No. But in Complete Mode, restarted query will recreate the full table. | Table name is the query name. |
Note that you have to call start() to actually start the execution of the query. This returns a StreamingQuery object which is a handle to the continuously running execution. You can use this object to manage the query, which we will discuss in the next subsection. For now, let’s understand all this with a few examples.
注意,必须调用 start()才能实际开始执行查询。这将返回一个 StreamingQuery 对象,该对象是连续运行执行的句柄。您可以使用这个对象来管理查询,我们将在下一小节中讨论这个问题。现在,让我们用几个例子来理解这一切。
1 | // ========== DF with no aggregations ========== |
Using Foreach and ForeachBatch
使用Foreach和ForeachBatch
The foreach and foreachBatch operations allow you to apply arbitrary operations and writing logic on the output of a streaming query. They have slightly different use cases - while foreach allows custom write logic on every row, foreachBatch allows arbitrary operations and custom logic on the output of each micro-batch. Let’s understand their usages in more detail.
foreach和 foreachBatch 操作允许您对流式查询的输出应用任意操作和写入逻辑。它们有稍微不同的用例——虽然 foreach 允许在每一行上自定义写入逻辑,但是 foreachBatch 允许在每个微批的输出上执行任意操作和自定义逻辑。让我们更详细地了解它们的用法。
ForeachBatch
foreachBatch(...) allows you to specify a function that is executed on the output data of every micro-batch of a streaming query. Since Spark 2.4, this is supported in Scala, Java and Python. It takes two parameters: a DataFrame or Dataset that has the output data of a micro-batch and the unique ID of the micro-batch.
foreachBatch(...)允许您指定对流式查询的每个微批的输出数据执行的函数。由于 Spark 2.4,这是支持在 Scala,Java 和 Python。它需要两个参数:一个 DataFrame/Dataset,该 DataFrame/Dataset 具有微批的输出数据和微批的唯一ID。
1 | streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) => |
With foreachBatch, you can do the following.
使用 foreachBatch,你可以作如下事情:
Reuse existing batch data sources - For many storage systems, there may not be a streaming sink available yet, but there may already exist a data writer for batch queries. Using
foreachBatch, you can use the batch data writers on the output of each micro-batch.重用现有的批处理数据源——对于许多存储系统,可能还没有可用的流接收器,但可能已经存在用于批处理查询的数据编写器。使用
foreachBatch,可以在每个微批的输出上使用批处理数据编写器。Write to multiple locations - If you want to write the output of a streaming query to multiple locations, then you can simply write the output DataFrame/Dataset multiple times. However, each attempt to write can cause the output data to be recomputed (including possible re-reading of the input data). To avoid recomputations, you should cache the output DataFrame/Dataset, write it to multiple locations, and then uncache it. Here is an outline.
写入多个位置——如果要将流式查询的输出写入多个位置,则只需多次写入输出 DataFrame/Dataset。但是,每次尝试写入都会导致重新计算输出数据(包括可能重新读取输入数据)。为了避免重新计算,应该缓存输出 DataFrame/Dataset,将其写入多个位置,然后取消缓存。这里一个大纲。
1
2
3
4
5
6
7streamingDF.writeStream.foreachBatch {
(batchDF: DataFrame, batchId: Long) =>
batchDF.persist()
batchDF.write.format(…).save(…) // location 1
batchDF.write.format(…).save(…) // location 2
batchDF.unpersist()
}Apply additional DataFrame operations - Many DataFrame and Dataset operations are not supported in streaming DataFrames because Spark does not support generating incremental plans in those cases. Using
foreachBatch, you can apply some of these operations on each micro-batch output. However, you will have to reason about the end-to-end semantics of doing that operation yourself.应用其他 DataFrame 操作——流式 DataFrame 中不支持许多 DataFrame 和 Dataset 操作,因为 Spark 在这些情况下不支持生成增量计划(generating incremental plans)。使用
foreachBatch,可以对每个微批处理输出应用其中一些操作。但是,您必须对自己执行该操作的端到端语义进行推理。
Note:
By default,
foreachBatchprovides only at-least-once write guarantees. However, you can use the batchId provided to the function as way to deduplicate the output and get an exactly-once guarantee.默认情况下,
foreachBatch至少提供一次写入保证。但是,您可以使用提供给函数的 batchId 作为消除重复输出并获得一次性保证的方法。foreachBatchdoes not work with the continuous processing mode as it fundamentally relies on the micro-batch execution of a streaming query. If you write data in the continuous mode, useforeachinstead.foreachBatch不使用连续处理模式,因为它从根本上依赖于流式查询的微批处理执行。如果以连续模式写入数据,请改用foreach。
Foreach
If foreachBatch is not an option (for example, corresponding batch data writer does not exist, or continuous processing mode), then you can express you custom writer logic using foreach. Specifically, you can express the data writing logic by dividing it into three methods: open, process, and close. Since Spark 2.4, foreach is available in Scala, Java and Python.
如果 foreachBatch 不是一个选项(例如,相应的批数据编写器不存在,或者不存在连续处理模式),则可以使用 foreach 表示自定义编写器的逻辑。具体来说,您可以将数据写入逻辑划分为三种方法:打开、处理和关闭。自从 Scale 2.4 以来,foreach 在 Scala、Java 和 Python 中可用。
In Scala, you have to extend the class ForeachWriter (docs).
在 Scala 中,必须扩展 ForeachWriter 类(文档)。
1 | streamingDatasetOfString.writeStream.foreach( |
Execution semantics When the streaming query is started, Spark calls the function or the object’s methods in the following way :
执行语义 当启动流式查询时,Spark以下方式调用函数或对象的方法:
A single copy of this object is responsible for all the data generated by a single task in a query. In other words, one instance is responsible for processing one partition of the data generated in a distributed manner.
此对象的单个副本负责查询中单个任务生成的所有数据。换句话说,一个实例负责处理以分布式方式生成的数据的一个分区。
This object must be serializable, because each task will get a fresh serialized-deserialized copy of the provided object. Hence, it is strongly recommended that any initialization for writing data (for example. opening a connection or starting a transaction) is done after the open() method has been called, which signifies that the task is ready to generate data.
此对象必须是可序列化的,因为每个任务都将获得所提供对象的新的序列化反序列化副本。因此,强烈建议对写入数据进行任何初始化(例如。打开连接或启动事务)是在调用
open方法之后完成的,这预示着任务已准备好生成数据。The lifecycle of the methods are as follows:
方法的生命周期如下:
For each partition with
partition_id:对于具有分区ID的每个分区:
For each batch/epoch of streaming data with epoch_id:
对于具有
epoch_id的流式数据的每个批/时期:Method
open(partitionId, epochId)is called.方法
open(partitionId, epochId)被调用。If
open(…)returns true, for each row in the partition and batch/epoch, method process(row) is called.如果
open(…)返回 true,则对分区和批处理/轮(epoch)中的每一行调用方法process(row)。Method
close(error)is called with error (if any) seen while processing rows.调用方法
close(error),处理行时出现错误(如果有)。
The
close()method (if it exists) is called if anopen()method exists and returns successfully (irrespective of the return value), except if the JVM or Python process crashes in the middle.除了如果JVM或Python进程在中间崩溃之外,如果存在一个
open()方法且返回成功(不限制返回值),则调用close()方法。Note: The
partitionIdandepochIdin theopen()method can be used to deduplicate generated data when failures cause reprocessing of some input data. This depends on the execution mode of the query. If the streaming query is being executed in the micro-batch mode, then every partition represented by a unique tuple(partition_id, epoch_id)is guaranteed to have the same data. Hence, (partition_id, epoch_id) can be used to deduplicate and/or transactionally commit data and achieve exactly-once guarantees. However, if the streaming query is being executed in the continuous mode, then this guarantee does not hold and therefore should not be used for deduplication.注意:当失败导致重新处理某些输入数据时,
open()方法中的partitionId和epochId可用于对生成的数据进行重复数据消除。这取决于查询的执行模式。如果流式查询是在微批处理模式下执行的,那么由一个唯一元组(partition_id,epoch_id)表示的每个分区都保证具有相同的数据。因此,(partition_id, epoch_id)可用于消除重复和/或事务性提交数据,并实现一次性保证。但是,如果流式查询是在连续模式下执行的,则此保证不适用,因此不应用于重复数据消除。Triggers
触发器The trigger settings of a streaming query defines the timing of streaming data processing, whether the query is going to executed as micro-batch query with a fixed batch interval or as a continuous processing query. Here are the different kinds of triggers that are supported.
流式查询的触发器设置定义了流式数据处理的时间,无论该查询是作为具有固定批处理间隔的微批处理查询还是作为连续处理查询执行。以下是支持的不同类型的触发器。
| Trigger Type | Description |
|---|---|
| unspecified (default) |
If no trigger setting is explicitly specified, then by default, the query will be
executed in micro-batch mode, where micro-batches will be generated as soon as
the previous micro-batch has completed processing.
如果未显式指定触发器设置,则默认情况下,查询将以微批处理模式执行,在微批处理完成后,将立即生成微批。 |
| Fixed interval micro-batches |
The query will be executed with micro-batches mode, where micro-batches will be kicked off
at the user-specified intervals.
查询将以微批处理模式执行,微批处理将按用户指定的时间间隔启动。
|
| One-time micro-batch |
The query will execute only one micro-batch to process all the available data and then
stop on its own. This is useful in scenarios you want to periodically spin up a cluster,
process everything that is available since the last period, and then shutdown the
cluster. In some case, this may lead to significant cost savings.
查询将只执行一个微批处理,以处理所有可用数据,然后自行停止。这在您希望定期启动集群、处理自上一个周期以来可用的所有内容,然后关闭集群的场景中非常有用。在某些情况下,这可能导致显著的成本节约。 |
| Continuous with fixed checkpoint interval (experimental) |
The query will be executed in the new low-latency, continuous processing mode. Read more
about this in the Continuous Processing section below.
查询将以新的低延迟、连续处理模式执行。请在下面的“连续处理”部分中阅读有关此内容的更多信息。 |
Here are a few code examples.
这里有一些代码例子。
1 | import org.apache.spark.sql.streaming.Trigger |
Managing Streaming Queries
管理流查询
The StreamingQuery object created when a query is started can be used to monitor and manage the query.
启动查询时创建的 StreamingQuery 对象可用于监视和管理查询。
1 | val query = df.writeStream.format("console").start() // get the query object |
You can start any number of queries in a single SparkSession. They will all be running concurrently sharing the cluster resources. You can use sparkSession.streams() to get the StreamingQueryManager (Scala/Java/Python docs) that can be used to manage the currently active queries.
您可以在单个 SparkSession 中启动任意数量的查询。它们都将同时运行,共享集群资源。您可以使用sparkSession.streams() 来获得 StreamingQueryManager(Scala/Java/Python 文档),可以用来管理当前活动的查询。
1 | val spark: SparkSession = ... |
Monitoring Streaming Queries
监控流查询
There are multiple ways to monitor active streaming queries. You can either push metrics to external systems using Spark’s Dropwizard Metrics support, or access them programmatically.
有多种方法可以监视活动的流式查询。您可以使用 Spark 的 Dropwizard Metrics 支持将量化指标推送到外部系统,也可以通过编程方式访问它们。
Reading Metrics Interactively
交互式读取量化指标
You can directly get the current status and metrics of an active query using streamingQuery.lastProgress() and streamingQuery.status().lastProgress() returns a StreamingQueryProgress object in Scala and Java and a dictionary with the same fields in Python. It has all the information about the progress made in the last trigger of the stream - what data was processed, what were the processing rates, latencies, etc. There is also streamingQuery.recentProgress which returns an array of last few progresses.
您可以在 Scala , Java 以及 Python中拥有相同字段的字典使用 streamingQuery.lastProgress() 和 streamingQuery.status().lastProgress() 返回一个 StreamingQueryProgress 对象来直接获取一个处于激活状态的查询的当前状态和量化标准。它包含有关流上一个触发器中的进展的所有信息——处理了哪些数据、处理速率、延迟等。还有 streamingQuery.recentProgress,它返回最后几个进度的数组。
In addition, streamingQuery.status() returns a StreamingQueryStatus object in Scala and Java and a dictionary with the same fields in Python. It gives information about what the query is immediately doing - is a trigger active, is data being processed, etc.
此外,streamingQuery.status() 在 Scala 和 Java 中返回一个流化 StreamingQueryStatus 对象,并在Python中返回一个具有相同字段的字典。它提供有关查询正在立即执行的操作的信息——触发器是否处于活动状态、数据是否正在处理等。
Here are a few examples.
下面是几个例子。
1 | val query: StreamingQuery = ... |
Reporting Metrics programmatically using Asynchronous APIs
使用异步API以编程方式报告量化指标
You can also asynchronously monitor all queries associated with a SparkSession by attaching a StreamingQueryListener (Scala/Java docs). Once you attach your custom StreamingQueryListener object with sparkSession.streams.attachListener(), you will get callbacks when a query is started and stopped and when there is progress made in an active query. Here is an example,
还可以通过附加 StreamingQueryListener(Scala/Java 文档)来异步监视与 SparkSession 相关联的所有查询。使用 sparkSession.streams.attachListener() 附加自定义 StreamingQueryListener 对象后,当查询启动和停止以及活动查询中有进展时,您将得到回调。下面是一个例子,
1 | val spark: SparkSession = ... |
Reporting Metrics using Dropwizard
使用 DropWizard 报告量化指标
Spark supports reporting metrics using the Dropwizard Library. To enable metrics of Structured Streaming queries to be reported as well, you have to explicitly enable the configuration spark.sql.streaming.metricsEnabled in the SparkSession.
Spark支持使用 DropWizard 库指标量化。要同时使结构化流式查询的量化指标可用,必须显式启用 SparkSession 中启用的配置 spark.sql.streaming.metricsEnabled。
1 | spark.conf.set("spark.sql.streaming.metricsEnabled", "true") |
All queries started in the SparkSession after this configuration has been enabled will report metrics through Dropwizard to whatever sinks have been configured (e.g. Ganglia, Graphite, JMX, etc.).
启用此配置后在 SparkSession 中启动的所有查询都将通过 DropWizard 向已配置的任何接收器(例如 Ganglia、Graphite、JMX等)报告量化指标。
Recovering from Failures with Checkpointing
使用检查点从失败中恢复
In case of a failure or intentional shutdown, you can recover the previous progress and state of a previous query, and continue where it left off. This is done using checkpointing and write-ahead logs. You can configure a query with a checkpoint location, and the query will save all the progress information (i.e. range of offsets processed in each trigger) and the running aggregates (e.g. word counts in the quick example) to the checkpoint location. This checkpoint location has to be a path in an HDFS compatible file system, and can be set as an option in the DataStreamWriter when starting a query.
如果出现故障或有意关闭,可以恢复以前查询的进度和状态,并在停止的地方继续。这是使用检查点和提前写入日志完成的。您可以使用检查点位置配置查询,该查询将把所有进度信息(即每个触发器中处理的偏移范围)和正在运行的聚合(如快速示例中的字数)保存到检查点位置。此检查点位置必须是HDFS兼容文件系统中的路径,并且可以在启动查询时在 DataStreamWriter 中设置为选项。
1 | aggDF |
Recovery Semantics after Changes in a Streaming Query
流式查询更改后的恢复语义
There are limitations on what changes in a streaming query are allowed between restarts from the same checkpoint location. Here are a few kinds of changes that are either not allowed, or the effect of the change is not well-defined. For all of them :
在从同一检查点位置重新启动之间,流式查询中允许哪些更改受到限制。以下是一些不允许的更改,或者更改的效果没有很好的定义。对于所有人:
The term allowed means you can do the specified change but whether the semantics of its effect is well-defined depends on the query and the change.
术语allowed意味着您可以进行指定的更改,但其效果的语义是否定义良好取决于查询和更改。
The term not allowed means you should not do the specified change as the restarted query is likely to fail with unpredictable errors.
sdfrepresents a streaming DataFrame/Dataset generated withsparkSession.readStream.术语“不允许”意味着您不应该进行指定的更改,因为重新启动的查询可能会失败,并出现不可预知的错误。
sdf表示使用流式sparkSession.readStream生成的流式 DataFrame/Dataset。
Types of changes
Changes in the number or type (i.e. different source) of input sources: This is not allowed.
输入源的编号或类型(即不同的源)发生更改:这是不允许的。
Changes in the parameters of input sources: Whether this is allowed and whether the semantics of the change are well-defined depends on the source and the query. Here are a few examples.
输入源参数的更改:是否允许,更改的语义是否定义良好,取决于源和查询。
Addition/deletion/modification of rate limits is allowed:
允许添加/删除/修改速率限制:
spark.readStream.format("kafka").option("subscribe", "topic")tospark.readStream.format("kafka").option("subscribe", "topic").option("maxOffsetsPerTrigger", ...)Changes to subscribed topics/files is generally not allowed as the results are unpredictable:
通常不允许更改订阅的主题/文件,因为结果不可预测:
spark.readStream.format("kafka").option("subscribe", "topic")tospark.readStream.format("kafka").option("subscribe", "newTopic")
Changes in the type of output sink: Changes between a few specific combinations of sinks are allowed. This needs to be verified on a case-by-case basis. Here are a few examples.
输出接收器类型的更改:允许在几个特定接收器组合之间进行更改。这需要逐个验证。下面是几个例子。
File sink to Kafka sink is allowed. Kafka will see only the new data.
允许文件接收器到 Kafka 接收器。Kafka 只能看到新的数据。
Kafka sink to file sink is not allowed.
不允许 Kafka 接收器到文件接收器。
Kafka sink changed to foreach, or vice versa is allowed.
Kafka 接收器改为 foreach,反之亦然,都是允许的。
Changes in the parameters of output sink: Whether this is allowed and whether the semantics of the change are well-defined depends on the sink and the query. Here are a few examples.
输出接收器参数的更改:是否允许,更改的语义是否定义良好,取决于接收器和查询。下面是几个例子。
Changes to output directory of a file sink is not allowed:
不允许更改文件接收器的输出目录:
sdf.writeStream.format("parquet").option("path", "/somePath")tosdf.writeStream.format("parquet").option("path", "/anotherPath")Changes to output topic is allowed:
允许更改输出主题:
sdf.writeStream.format("kafka").option("topic", "someTopic")tosdf.writeStream.format("kafka").option("topic", "anotherTopic")Changes to the user-defined foreach sink (that is, the
ForeachWritercode) is allowed, but the semantics of the change depends on the code.允许更改用户定义的 foreach 接收器(即
Foreachwriter代码),但更改的语义取决于代码。
Changes in projection / filter / map-like operations: Some cases are allowed. For example:
投影/过滤/映射类的操作中的更改:某些情况下是允许的。例如:
Addition / deletion of filters is allowed :
允许添加/删除筛选器:
sdf.selectExpr("a")tosdf.where(...).selectExpr("a").filter(...).Changes in projections with same output schema is allowed:
允许更改具有相同输出架构的投影:
sdf.selectExpr("stringColumn AS json").writeStreamtosdf.selectExpr("anotherStringColumn AS json").writeStreamChanges in projections with different output schema are conditionally allowed:
有条件地允许使用不同输出架构的投影中的更改:
sdf.selectExpr("a").writeStreamtosdf.selectExpr("b").writeStreamis allowed only if the output sink allows the schema change from"a"to"b".sdf.selectExpr("a").writeStream到sdf.selectExpr("b").writeStream。只有在输出接收器允许模式从“a”更改为“b”时才允许使用。
Changes in stateful operations: Some operations in streaming queries need to maintain state data in order to continuously update the result. Structured Streaming automatically checkpoints the state data to fault-tolerant storage (for example, HDFS, AWS S3, Azure Blob storage) and restores it after restart. However, this assumes that the schema of the state data remains same across restarts. This means that any changes (that is, additions, deletions, or schema modifications) to the stateful operations of a streaming query are not allowed between restarts. Here is the list of stateful operations whose schema should not be changed between restarts in order to ensure state recovery:
状态操作中的更改:流式查询中的某些操作需要维护状态数据,以便持续更新结果。结构化流自动检查状态数据到容错存储(例如,HDFS、AWS S3、Azure Blob存储)并在重新启动后将其还原。但是,这是假设状态数据的模式在重新启动时保持不变。这意味着在重新启动之间不允许对流式查询的有状态操作进行任何更改(即添加、删除或架构修改)。以下是为确保状态恢复,在重新启动之间不应更改其模式的有状态操作列表:
Streaming aggregation: For example,
sdf.groupBy("a").agg(...). Any change in number or type of grouping keys or aggregates is not allowed.流聚合:例如,
sdf.groupBy("a").agg(...)。不允许对分组键或聚合的数量或类型进行任何更改。Streaming deduplication: For example,
sdf.dropDuplicates("a"). Any change in number or type of grouping keys or aggregates is not allowed.流式重复数据消除:例如,
sdf.dropDuplicates("a")。不允许对分组键或聚合的数量或类型进行任何更改。Stream-stream join: For example,
sdf1.join(sdf2, ...)(i.e. both inputs are generated withsparkSession.readStream). Changes in the schema or equi-joining columns are not allowed. Changes in join type (outer or inner) not allowed. Other changes in the join condition are ill-defined.流流连接:例如,
sdf1.join(sdf2, ...)(即,两个输入都是用sparkSession.readStream生成的)。不允许更改模式或同等连接列。不允许更改连接类型(外部或内部)。连接条件中的其他更改定义错误。Arbitrary stateful operation: For example,
sdf.groupByKey(...).mapGroupsWithState(...)orsdf.groupByKey(...).flatMapGroupsWithState(...). Any change to the schema of the user-defined state and the type of timeout is not allowed. Any change within the user-defined state-mapping function are allowed, but the semantic effect of the change depends on the user-defined logic. If you really want to support state schema changes, then you can explicitly encode/decode your complex state data structures into bytes using an encoding/decoding scheme that supports schema migration. For example, if you save your state as Avro-encoded bytes, then you are free to change the Avro-state-schema between query restarts as the binary state will always be restored successfully.sdf.groupByKey(...).mapGroupsWithState(...)或sdf.groupByKey(...).flatMapGroupsWithState(...)。不允许对用户定义状态的模式和超时类型进行任何更改。允许在用户定义的状态映射函数中进行任何更改,但更改的语义效果取决于用户定义的逻辑。如果您真的希望支持状态模式更改,那么您可以使用支持模式迁移的编码/解码方案将复杂的状态数据结构显式编码/解码为字节。例如,如果将状态保存为 Avro 编码的字节,则可以在查询重新启动之间自由更改 Avro 状态模式,因为二进制状态将始终成功还原。
Continuous Processing
连续处理
[Experimental] 实验性的
Continuous processing is a new, experimental streaming execution mode introduced in Spark 2.3 that enables low (~1 ms) end-to-end latency with at-least-once fault-tolerance guarantees. Compare this with the default micro-batch processing engine which can achieve exactly-once guarantees but achieve latencies of ~100ms at best. For some types of queries (discussed below), you can choose which mode to execute them in without modifying the application logic (i.e. without changing the DataFrame/Dataset operations).
连续处理是 Spark 2.3 中引入的一种新的、实验性的流式执行模式,它支持低(约 1 ms)端到端延迟,并至少保证一次容错。将其与默认的微批处理引擎进行比较,该引擎可以实现准确的一次保证,但最多只能实现约100毫秒的延迟。对于某些类型的查询(下面讨论),您可以选择在不修改应用程序逻辑的情况下执行它们的模式(即,不更改 DataFrame/Dataset 操作)。
To run a supported query in continuous processing mode, all you need to do is specify a continuous trigger with the desired checkpoint interval as a parameter. For example,
要在连续处理模式下运行受支持的查询,只需指定一个具有所需检查点间隔的连续触发器作为参数。例如,
1 | import org.apache.spark.sql.streaming.Trigger |
A checkpoint interval of 1 second means that the continuous processing engine will records the progress of the query every second. The resulting checkpoints are in a format compatible with the micro-batch engine, hence any query can be restarted with any trigger. For example, a supported query started with the micro-batch mode can be restarted in continuous mode, and vice versa. Note that any time you switch to continuous mode, you will get at-least-once fault-tolerance guarantees.
检查点间隔为1秒意味着连续处理引擎将每秒记录查询的进度。生成的检查点的格式与微批处理引擎兼容,因此任何查询都可以用任何触发器重新启动。例如,支持的以微批处理模式启动的查询可以在连续模式下重新启动,反之亦然。请注意,任何时候切换到连续模式时,至少会得到一次容错保证。
Supported Queries
支持的查询
As of Spark 2.3, only the following type of queries are supported in the continuous processing mode.
就 Spark 2.3 而言,只有以下类型的查询在连续处理模式中得到支持。
Operations : Only map-like Dataset/DataFrame operations are supported in continuous mode, that is, only projections (
select,map,flatMap,mapPartitions, etc.) and selections (where,filter, etc.).操作:只有映射类的 Dataset/DataFrame 操作在连续模式中受到支持,即,只有投影(
select,map,flatMap,mapPartitions等)和选择(where,filter等)。All SQL functions are supported except aggregation functions (since aggregations are not yet supported),
current_timestamp()andcurrent_date()(deterministic computations using time is challenging).所有SQL函数都支持除了聚集函数(因为聚集不支持)、
current_timestamp()和current_date()(使用时间的确定计算是一个挑战)。
Sources :
源
Kafka source: All options are supported.
Kafka 源:所有选项都得到支持。
Rate source: Good for testing. Only options that are supported in the continuous mode are
numPartitionsandrowsPerSecond.速率源:用于测试非常好。在连续模式中支持的唯一选项是
numPartitions和rowsPerSecond。
Sinks :
接收器
Kafka sink: All options are supported.
Kafka 源:所有选项都得到支持。
Memory sink: Good for debugging.
内存接收器:用于测试非常好。
Console sink: Good for debugging. All options are supported. Note that the console will print every checkpoint interval that you have specified in the continuous trigger.
控制台接收器:用以调试非常好。所有选项都支持。注意,控制台将在连续触发器中打印每一个特定的检查点间隔。
See Input Sources and Output Sinks sections for more details on them. While the console sink is good for testing, the end-to-end low-latency processing can be best observed with Kafka as the source and sink, as this allows the engine to process the data and make the results available in the output topic within milliseconds of the input data being available in the input topic.
查看输入源和输出接收器章节获取更多细节,当控制台接收器对测试很好时,使用Kafka作为源和接收器可以很好地观察终端到终端的低延迟处理,如允许引擎处理数据,并在输入主题可以得到的输入数据的几毫秒内使结果在(相应的)输出主题中可以得到。
Caveats
告警
Continuous processing engine launches multiple long-running tasks that continuously read data from sources, process it and continuously write to sinks. The number of tasks required by the query depends on how many partitions the query can read from the sources in parallel. Therefore, before starting a continuous processing query, you must ensure there are enough cores in the cluster to all the tasks in parallel. For example, if you are reading from a Kafka topic that has 10 partitions, then the cluster must have at least 10 cores for the query to make progress.
连续处理引擎启动多个长时间运行的任务,这些任务不断地从源读取数据、处理数据并不断地向接收器写入数据。查询所需的任务数取决于查询可以并行从源读取多少分区。因此,在开始连续处理查询之前,必须确保集群中有足够的核心来并行执行所有任务。例如,如果您正在读取具有10个分区的Kafka主题,那么集群必须至少有10个核心才能使查询取得进展。
Stopping a continuous processing stream may produce spurious task termination warnings. These can be safely ignored.
停止连续处理流可能会产生虚假的任务终止告警。这些可以被安全地忽略。
There are currently no automatic retries of failed tasks. Any failure will lead to the query being stopped and it needs to be manually restarted from the checkpoint.
当前没有失败任务的自动重试。任何失败都将导致查询停止,需要从检查点手动重新启动查询。
Additional Information
额外的信息
Further Reading 进一步的阅读
See and run the Scala/Java/Python/R examples.
- Instructions on how to run Spark examples
Read about integrating with Kafka in the Structured Streaming Kafka Integration Guide
与kafka集成请阅读 Structured Streaming Kafka Integration Guide
Read more details about using DataFrames/Datasets in the Spark SQL Programming Guide
Third-party Blog Posts 第三方 Blog,帖子
Talks
- Spark Summit Europe 2017
- Easy, Scalable, Fault-tolerant Stream Processing with Structured Streaming in Apache Spark - Part 1 slides/video, Part 2 slides/video
- Deep Dive into Stateful Stream Processing in Structured Streaming - slides/video
- Spark Summit 2016
- A Deep Dive into Structured Streaming - slides/video
